@kmadej Excellent thanks
We have setup a couple of sync servers and overall it seems to work have the feedback so far:
- Patient Attributes are not synced
- How can one disable the ability to sync from the parent? Can a global variable be setup for this?
- Audit Log:
- Additional filter and search options - by date (between dates), resource values (say Person named Stephen)
- Button to refresh the page - I use the browser refresh but would be great to have an action btton
- Sync Status page - what is queued, done - seems to be like the Audit Trail with those that are pending and have not been done yet .
- When viewing a message, can it be shown in a popup or on the same page, and can the details of the message be displayed
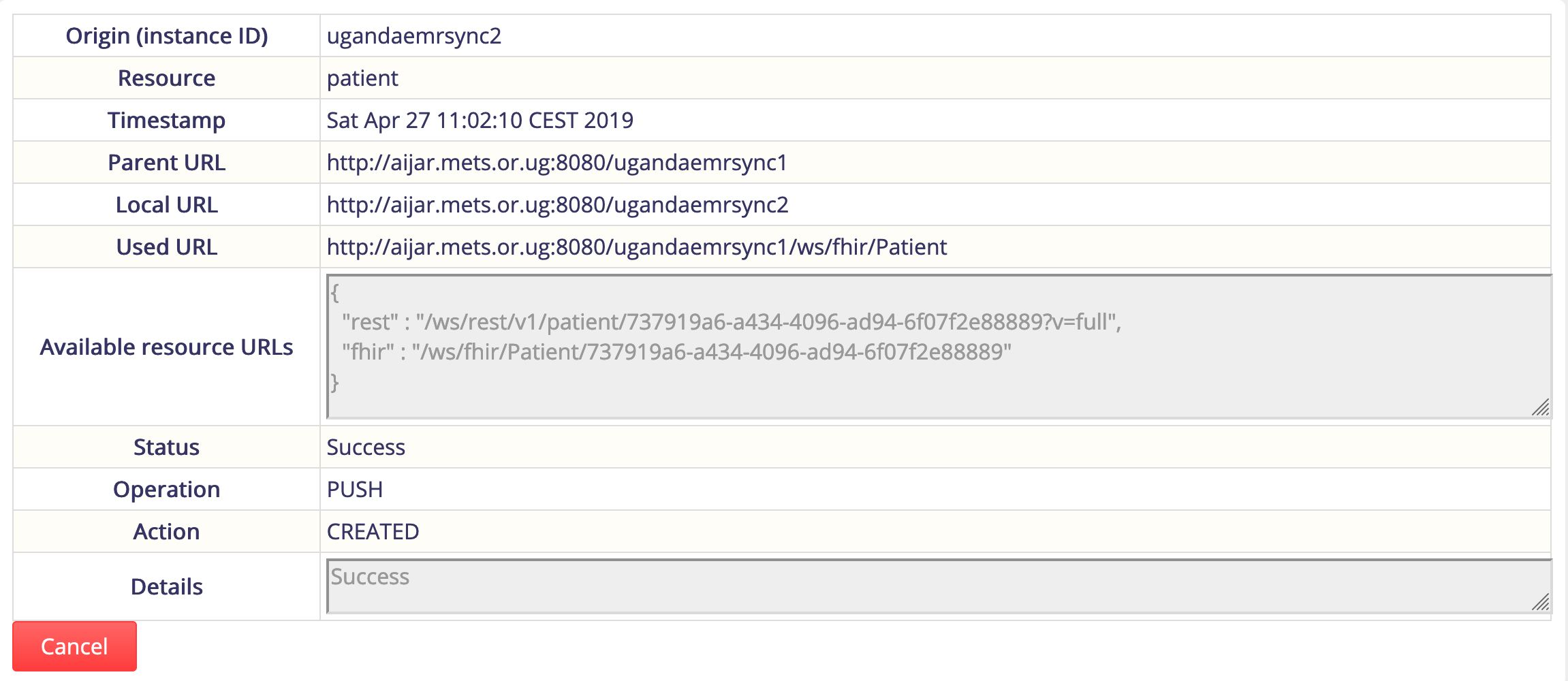
In the next 2-3 weeks the UgandaEMR team has an opportunity to leverage sync to merge two OpenMRS instances into one - so will look to leveraging the Sync Demo environment Docker to setup and run this. Will be sharing our experiences and learnings
3 Likes
Hi @ssmusoke , thanks a lot for your feedback, it is very valuable for us.
It will be great if you can put all the things which you find (or your suggestions) to the Sync 2.0 project backlog (link to the Jira space: https://issues.openmrs.org/projects/SYNCT/). It will be helpful if we will have all things in one place.
1 Like
@alalo I have created the tickets below as requested. Thanks for the good work with this module, its much appreciated
2 Likes
@alalo Some additional feedback
We have tried to use Sync to merge 2 OpenMRS instances that have the same metadata but have been used separately into a single parent, we ran into the following blockers:
-
Similar OpenMRS ID values - we use this as an auto-incrementing value to track patients (this can be deleted but they IDs cannot be used to uniquely identify a patient)
-
Numeric Encounter IDs conflict - this means that the encounters would overwrite each other, as they are passed in the messages
Maybe there is something we are not setting well, how does the sync work for elements with similar numeric IDs but different uuids (since these are expected to be globally unique)
Thanks in advance
Thank you very much for your feedback.
-
One of the solution which came to mind is to use the identifier prefix for that identifier type (" Manage Patient Identifier Sources" → “Configure OpenMRS ID” → prefix).
-
We didn’t notice that issue before, kindly create the bug for that in the project Jira space.
If you have any idea how to fix those issue feel free to made changes.
I’m adding to this thread as it seems to attract the right audience.
The server running sync servers is running out of disk for docker. You seem to have 2 containers that each one has almost 10GB of size (sync3refapp_openmrs-referenceapplication_1 and sync1refapp_openmrs-referenceapplication_1).
There’s nothing I can actually delete, so maybe you want to destroy/redeploy those containers before they eat all the disk 
cc @pkornowski
1 Like
Thank you very much for the information. I could take care of it.
However, 10GB (for each one) is a very huge size for those containers (those aren’t databases). Could you first try to identify what exactly consume those memories space? Or maybe can I get ssh access for those servers?
cc: @kmadej
There’s nothing inside those containers that are making them particularly big, so I think you might have a file or folder you are constantly writing and it’s not a docker volume. Maybe logs? Or something. It’s a little bit tricky for me to know which folders are constantly changing (and are on the container, not as a volume).
1 Like
Okay, thank you for investigation. I will try to use the OpenMRS Bamboo to destroy and redeploy all containers.
If this is not a problem please let us know if the situation happens again.
I redeployed mentioned Sync 2.0 containers. Anything should be right. Please let me know if not.
I additionally updated information about servers owner on that page: https://wiki.openmrs.org/display/ISM/OpenMRS+environments
1 Like
Thank you so much, @alalo. If I happen to see a problem on that, I will try to find out why, but our disk alerts were resolved.
But we have now CPU alarms ![]()
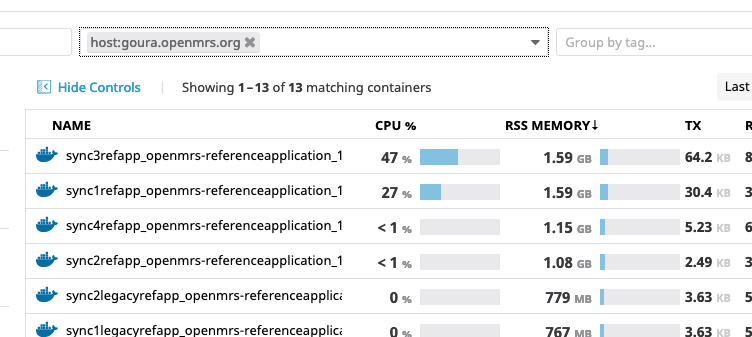
Both containers are eating a surprisingly amount of CPU. And it’s the java processes on both cases:
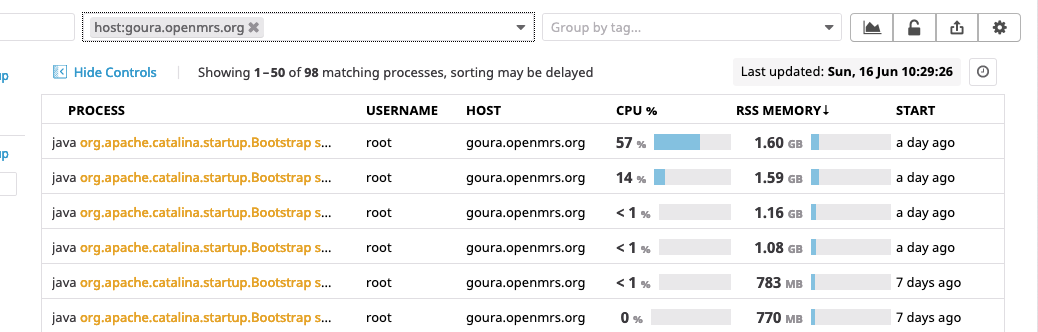
This seems wrong to me. I still seem to have enough free memory on the system to not think it’s garbage collection. Would you have any idea what’s the JVM/openmrs app is doing using so much CPU?
1 Like
Actually, scratch that.
java org.apache.catalina.startup.Bootstrap start -Djava.util.logging.config.file=/usr/local/tomcat/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Dfile.encoding=UTF-8 -server -Xms256m -Xmx768m -XX:PermSize=256m -XX:MaxPermSize=512m -Djdk.tls.ephemeralDHKeySize=2048 -agentlib:jdwp=transport -DOPENMRS_INSTALLATION_SCRIPT=/usr/local/tomcat/openmrs-server.properties -DOPENMRS_APPLICATION_DATA_DIRECTORY=/usr/local/tomcat/.OpenMRS -Dignore.endorsed.dirs= -classpath /usr/local/tomcat/bin/bootstrap.jar:/usr/local/tomcat/bin/tomcat-juli.jar -Dcatalina.base=/usr/local/tomcat -Dcatalina.home=/usr/local/tomcat -Djava.io.tmpdir=/usr/local/tomcat/temp
This is the command. I think you might be reaching your JVM limit. I think you need to increase the memory configuration a little bit (in theory, you still have 4GBs free on the machine in total).
Now it has become quiet again. I suppose the JVM managed to settle down.
Thanks for update.
I should have more time to take care of this at the end of the week.
We ran out of disk again
So I checked, and what’s happening is that the docker process is generating a lot of logs. Like, we are talking around more than 8GBs of logs per container.
A little bit excessive if you ask me
There are a lot of exceptions. I’d recommend you redeploy your containers, and make sure they are not so verbose.
Thank you for the update. I redeployed the containers again and decreased the log level. I hope this should help but if you noticed the issue please let me know.
Thanks in advance 
@alalo Just checking if there has been any work on the above mentioned tickets
I have placed two additional tickets based on this discussion
2 Likes