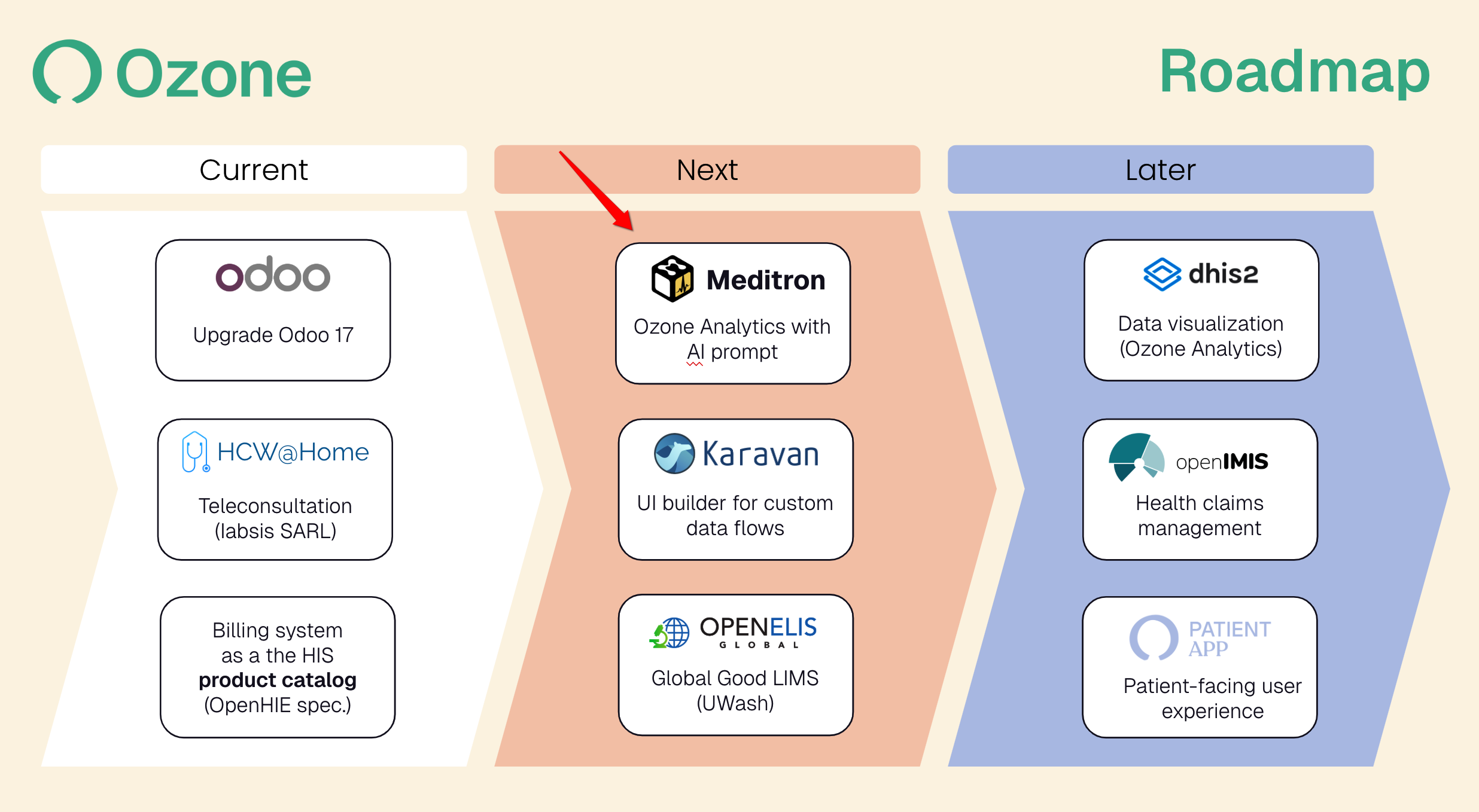
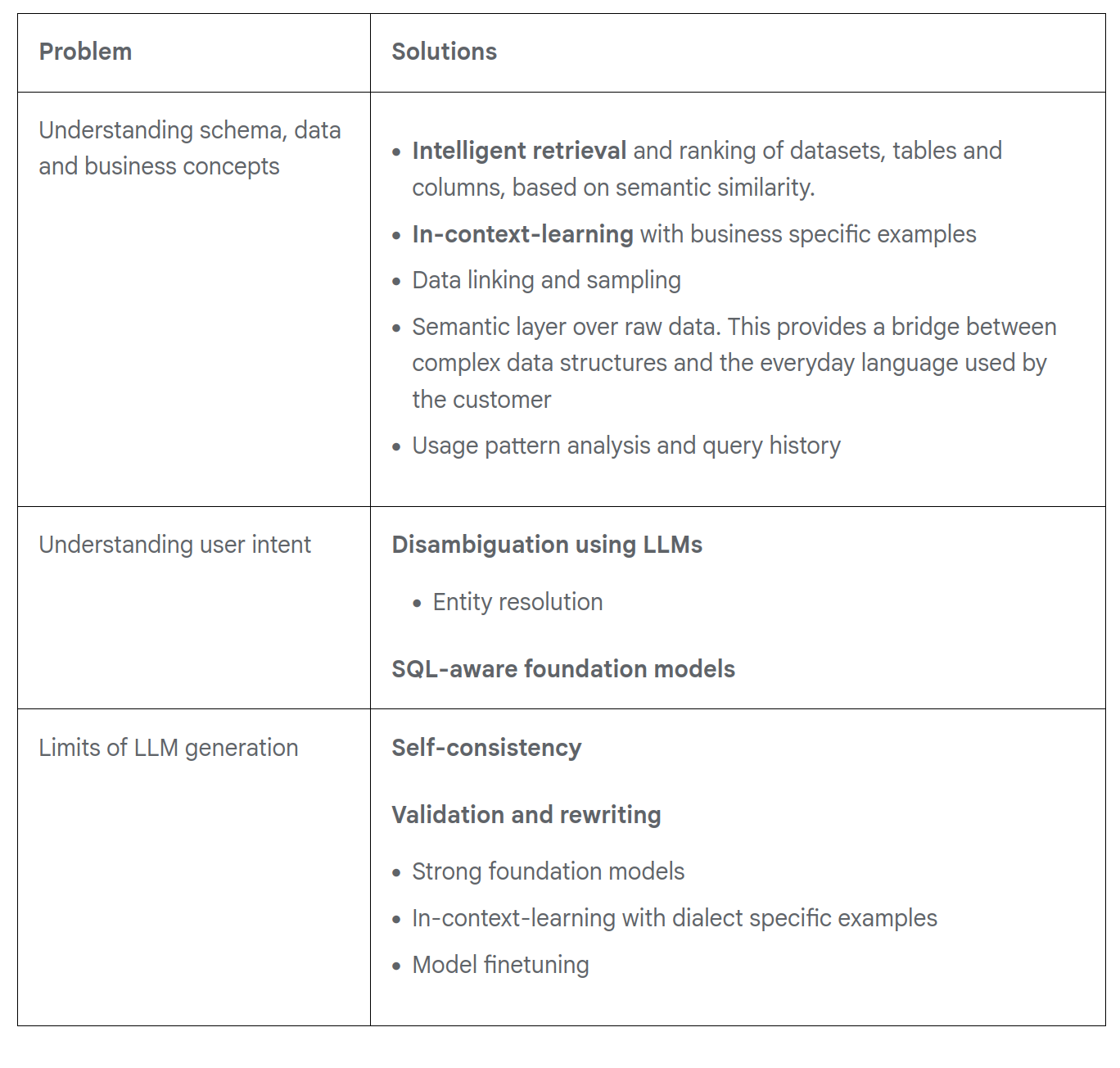
Hi,
Thank you all, these are very interesting developments.
LLMs seem at first glance to be a smart way to approach AI but we need to evaluate the trade offs there-in nad most importantly the usecases at hand.
Talking of text-to-sql/natutal language to sql , just to reference something that stood out to me from google research on the same;
TL;DR
So, I experimented with an MCP server for OpenMRS specifically looking at the OpenMRS data model with Claude (via openmrs-datamodel MCP server), and I encountered some of the problems above but with a significant improvement. You can check it out here ;
This aligns directly with what Google Cloud identified in their text-to-SQL challenges
- Need business/domain-specific context.
- Need intent disambiguation.
- Need SQL-aware generation and validation…
I did too fine-tune an SLM on sample OpenMRS queries and schema and the results were promising.
IMO:
tl;dr
Hybrid strategy: Use fine-tuned SLM for SQL reasoning + MCP for real schema context. And for general purpose usecases, we may need RAG as a retrieval layer with vector embeddings..
To ensure a low-risk entry point and one that aligns with the mission of low-resource settings, we need to be SLM-first or a hy-breed with MCP considerations too forward thinking and obviously with all experiments being done with LLMs no going. Something like the MCPs(OpenMRS, OCL/CIEL …) being the execution layer and the SLM(Domain centric) & FHIR-like standards the semantic layer/parser.
Forexample if there is an NL-to-SQL agent somewhat like what i talked about that is well grounded in the OpenMRS schema; simply put: having an SLM on-prem fine-tuned model trained with OpenMRS schema & and a family of tasks that we need to achieve then an LLM should be optional probably to come in for more complex natural language requests, but still wrapped with guardrails.
Raw LLMs don’t know OpenMRS even with a contextual prompt.
 Why this is big: MCP lets us stop “stuffing context” into prompts and instead bind models to the OpenMRS ecosystem in a clean, composable way. If we get this right, we can move from toy demos like mine*:*
Why this is big: MCP lets us stop “stuffing context” into prompts and instead bind models to the OpenMRS ecosystem in a clean, composable way. If we get this right, we can move from toy demos like mine*:* to a production-ready AI layer, powered by community standards.
to a production-ready AI layer, powered by community standards.