One of the main tasks for Add Ons is to implement a better search algorithm.
This post is a proposed solution for the issue here .
It takes into account whatever input we have got so far from the community include @mseaton, @darius and my points.
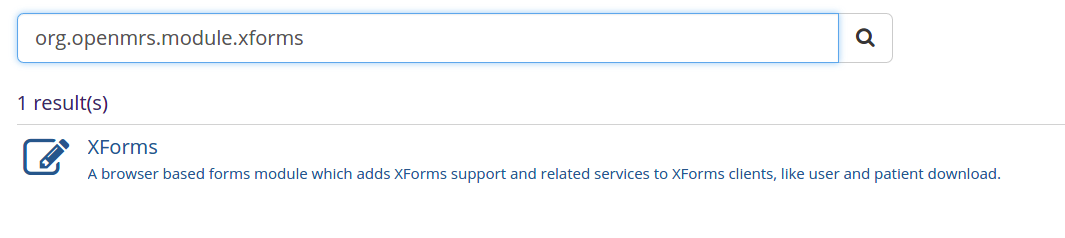
Now, when it comes to search criteria, we choose to limit our search to the type, tag, name/title, description of a module.
The algorithm also allows a bit of flexibility/mistakes while typing the search query.
The following points describe the circumstance and the action taken under that scenario:
If Query matches uid exactly then this search result is given the highest weight!
Query which matches title of module perfectly is given highest weight
Query which matches tag exactly given an equally high weight
* Ex: Query=”Form-Entry” and tag =”Form-Entry” then that module gets the top rank.
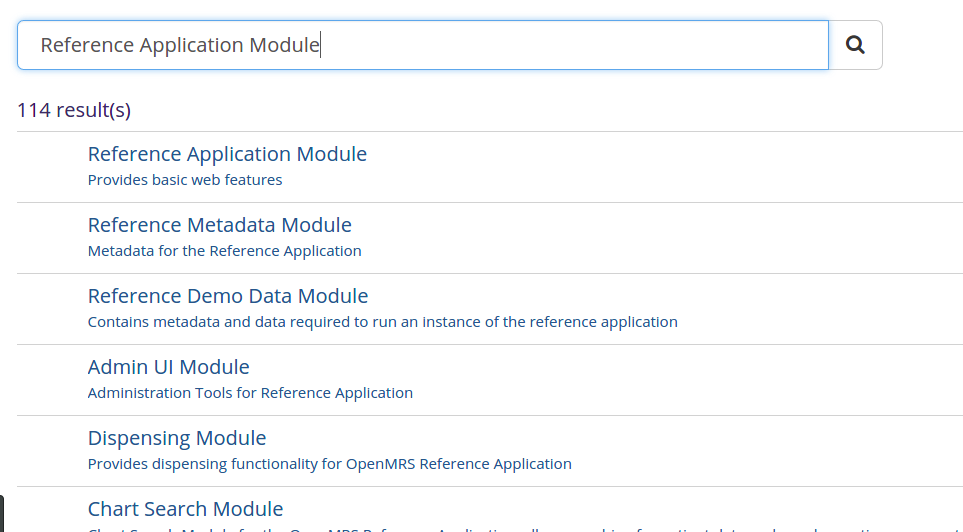
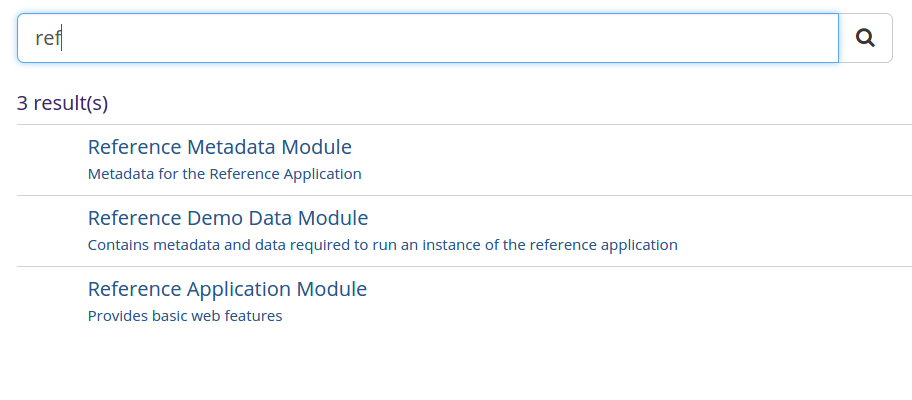
Query which is sub string of the title is also given a medium weight
* Ex: ref sub string of reference application ( Current algorithm is not implemented like this and hence it gets pushed down)
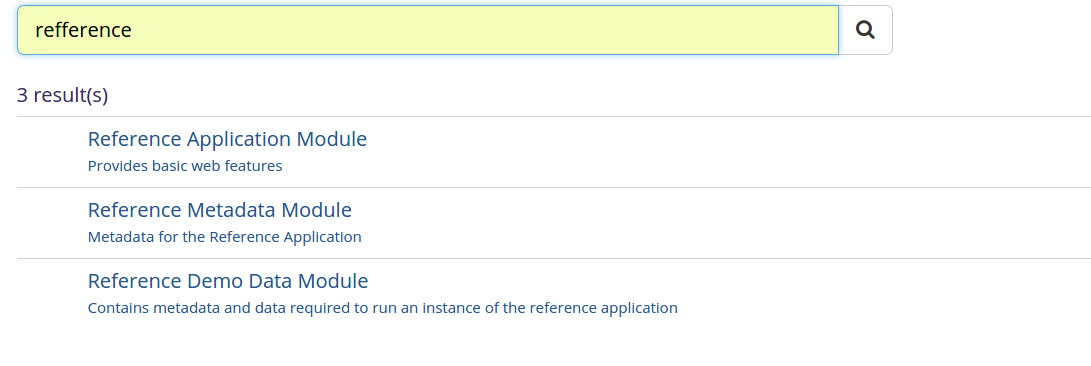
Query matching title using fuzziness=1(allows one spelling mistake) given low weight
Query which matches description as sub string given low weight
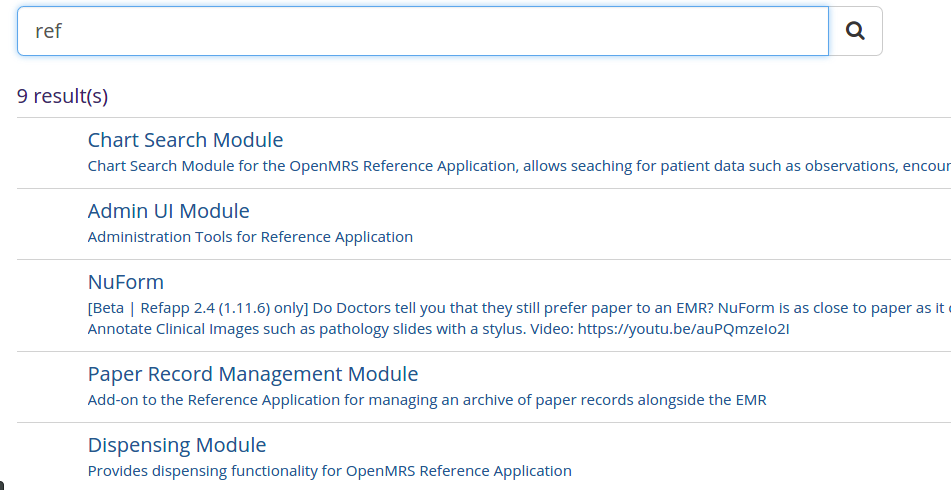
Reason is that many modules might contain the query as part of their description but only one will have it in it’s name and that module is given highest weightage. Example: “Reference Application” term is in the description of most ref app modules but it actually matches exactly with Reference application module. Moreover, when query=”ref”, modules with “ref “ in their title should rank higher than the ones with the term in their description
Query matching description using fuzziness given very low weight
Apart from the above :
Modules which are deprecated or inactive given least weight
If would like to add /suggest any changes, please feel free to reply to this post
So, we have been working on this for a while now. The main issue was ensuring that all the features work well together.
For example: If we give high rank to a name match then sometimes certain tag matches would be mistaken for a name match and hence the module with those tags would not show up first.
The solution?
Trial and error! This and a complete understanding of what each function does is the does only solution. The same is also mentioned in an elasticsearch documentation!
So after a few trials , we have come up with a proper algorithm which does the job.
Didn’t you say that there was still a limitation, and exact name matches aren’t working quite right yet? (And that we have to change the back-end data model and/or indexing in order to handle this?)
@darius Thanks for reminding me about that and also for the encouraging feedback !
Yes, we do have one limitation and that is currently, we have set the name of the field to be tokenized.
Now the problem with this is that say we have a module with the name “Reference application module”, then , elasticsearch stores it as 3 different words i.e. “Reference” , “Application” and “module” . Now suppose, the search query is “Reference” and we have other modules with similar names/ names with the search query in them like say “Metadata Reference module” . In such cases even though we’d like to see those modules with Reference as it’s first word ranked higher, elasticsearch cannot distinguish between these 2 cases and sometimes ranks the 2nd module higher.This is because elastic search that both module names contain the search query without realizing the order. This is not a desired feature.
What’s the solution?
The solution is to set the name field as “Not analyzed” i.e. basically we let elasticsearch that it is one single word and hence we tell elasticsearch to NOT tokenize it.
Then why haven’t we done it yet?
This is because we currently also make use of the fact that the words are being tokenized in building our search algorithm.
Then what’s the final solution?
We will have to create a duplicate field which will basically be a copy of the “Name” field and we will set it to “Not analyzed”