Recent Changes Update
Simulation Structure
- Simulation Tiers: Each simulation is divided into tiers, with each tier running for a specific duration. The user count increases gradually in each tier.
- GitHub Actions Scheduled Run: The tier duration is set to 30 minutes, with 6 tiers. Starting from 0 concurrent users, the count increases by 32 in each tier, reaching ~200 concurrent users in the last tier. These numbers are configurable, and you can define your own preset here.
Current Presets
| Preset |
Tier Count |
Tier Duration |
User Increment per Tier |
Ramp duration between tiers |
| Standard |
6 |
30 min |
32 |
1 min |
| Commit |
1 |
1 min |
20 |
1 min |
| Pull Request |
1 |
1 min |
20 |
1 min |
| Dev |
env TIER_COUNT |
env TIER_DURATION_MINUTES |
env USER_INCREMENT_PER_TIER |
1 min |
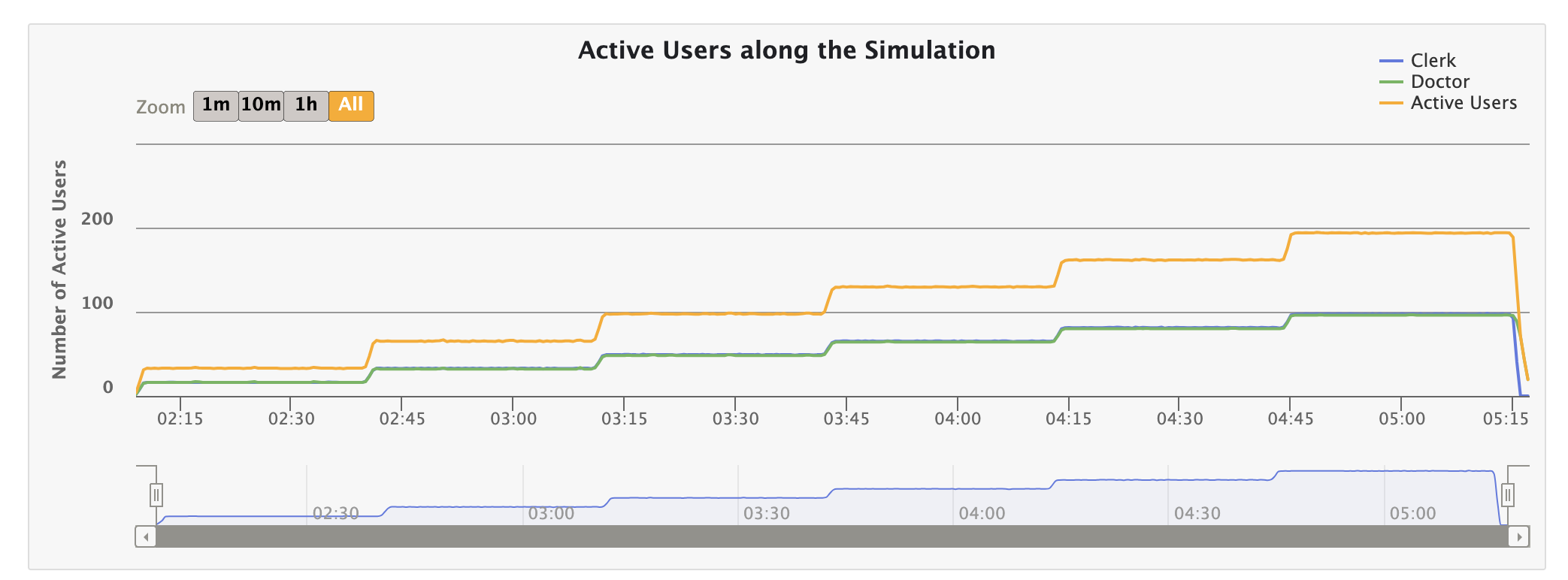
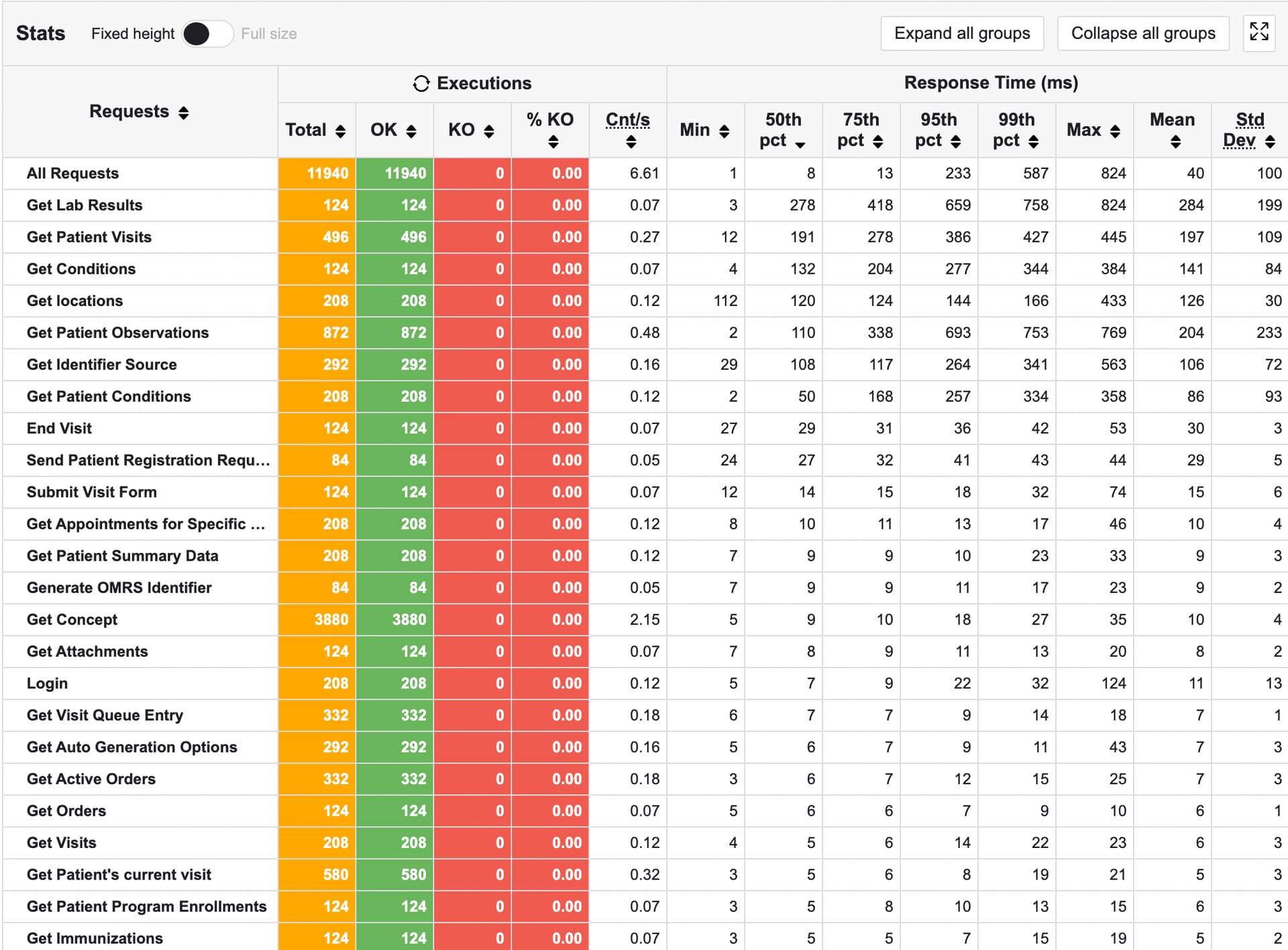
Active Users Over Time
Here’s a screenshot from the last report, showing the active users in the simulation over 3 hours:
Class Structure for Organization
To enforce better organization, I used a class structure with inheritance. More details are explained here.
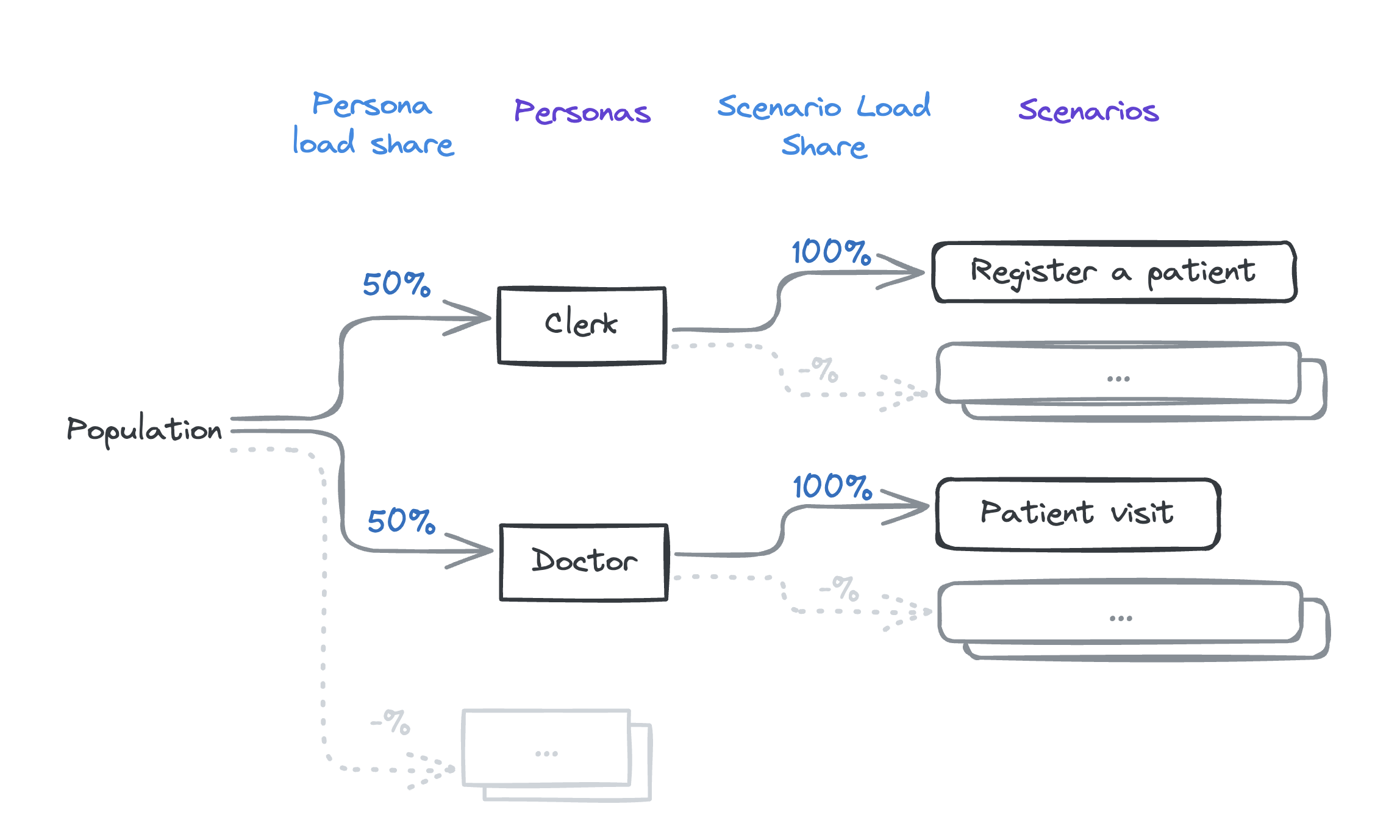
Personas and Scenarios
Here are the current personas and scenarios:
Observations and Analysis
Latest report: o3-performance.openmrs.org
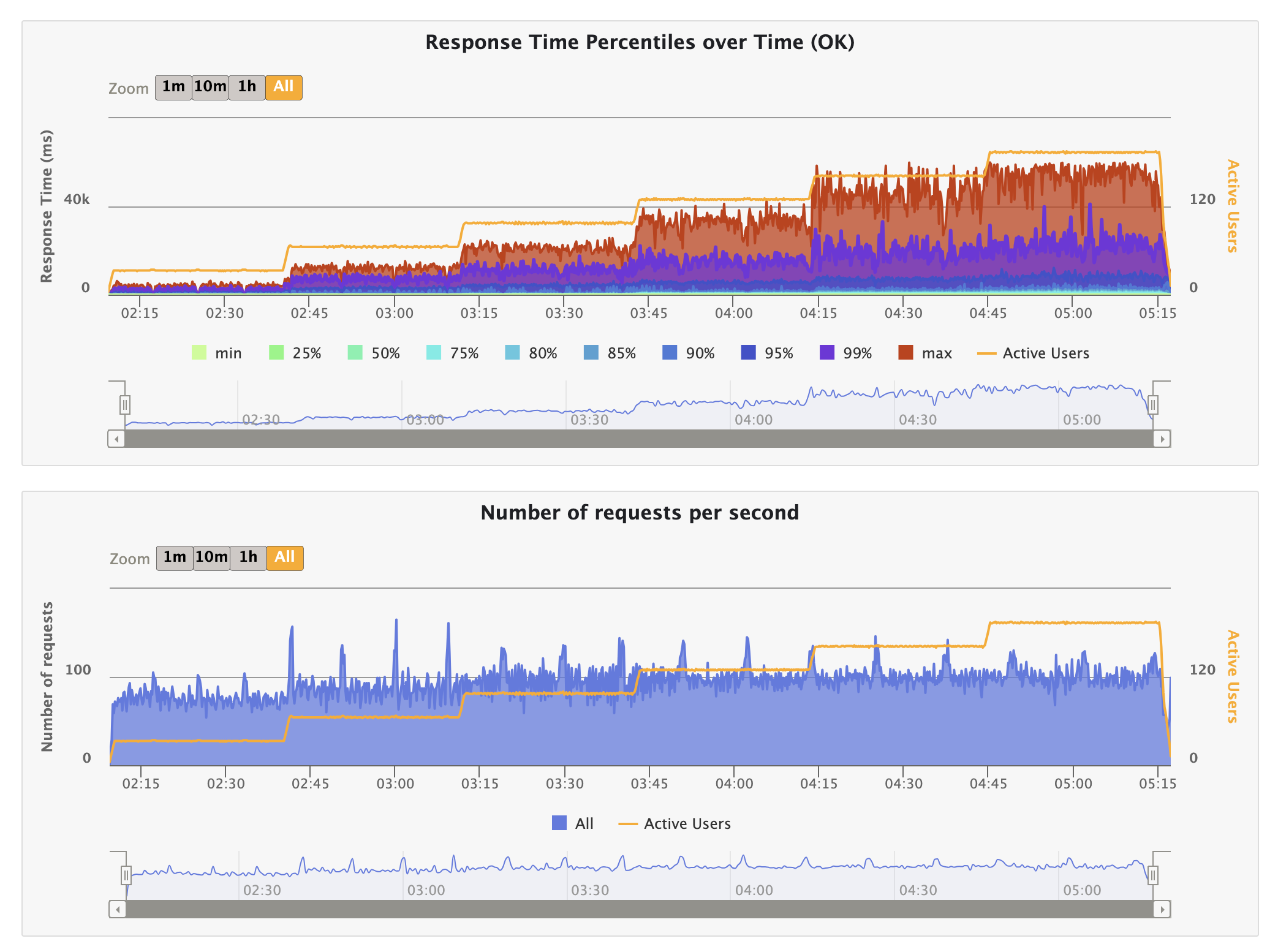
Response Time and Active Users
During the last platform call, we observed that response times increase with the number of active users. (Recording; Platform Meeting - Indiana University)
Here’s a screenshot illustrating this behavior:
Explanation of Behavior:
- Fixed Capacity of Java Server:
- The server can handle a limited number of requests per second based on hardware and network capabilities. E.g., if the server’s capacity is 120 requests per second, it can only process that many requests regardless of the number of users.
- Queueing Effect:
- As user numbers increase, more requests are made concurrently. Due to fixed processing capacity, additional requests must wait in a queue, leading to longer response times.
- Database Load:
- Increased user count leads to more database queries, which can slow down as it handles more concurrent operations, adding to the overall response time.
- Overall System Bottleneck:
- Both the Java server’s processing capacity and the database load contribute to the bottleneck. Even if one is fast, the other can cause increased response times if overloaded.
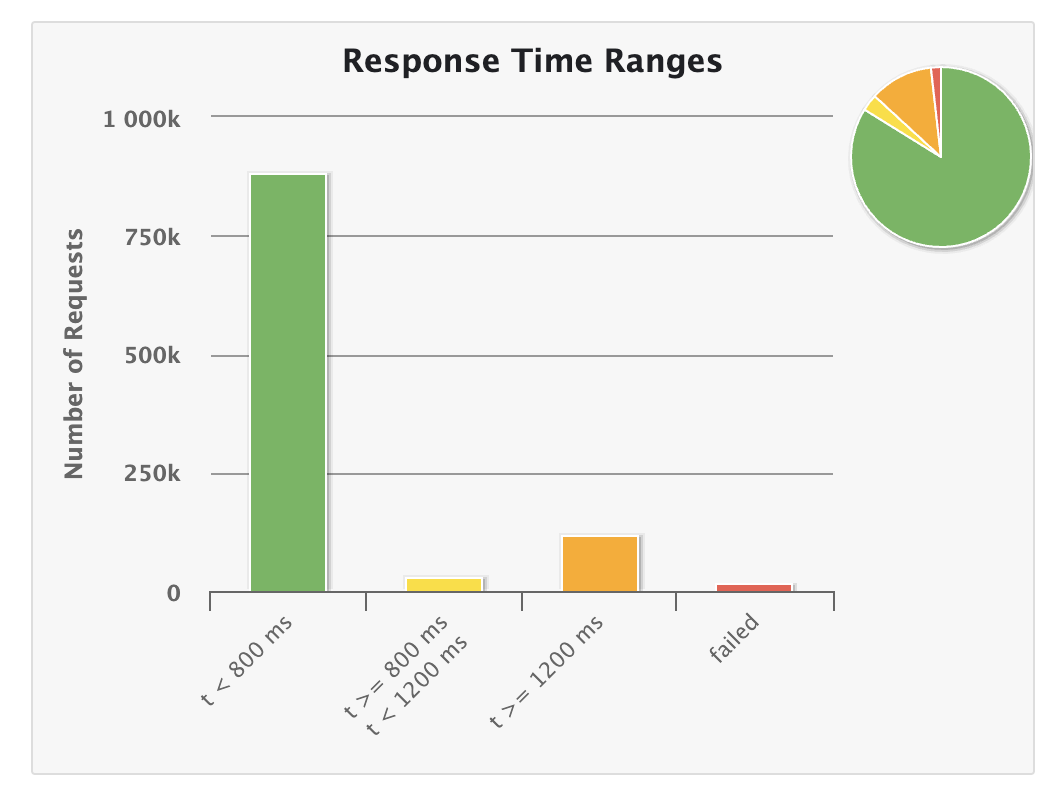
Response Time Thresholds
Based on our discussion and inputs from Ian, we decided to update the response time thresholds for the GitHub Action simulations as follows:
- Green: Less than 200ms
- Yellow: Between 200-1000ms
- Orange: More than 1000ms
These changes will be implemented in the next iteration.
This is how it currently shows;
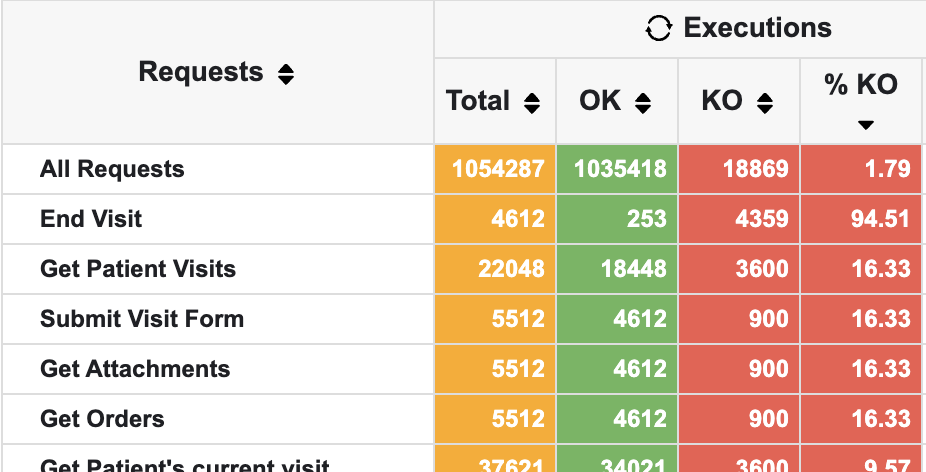
KO Count Analysis
We discussed the KO count (Knockout or opposite of OK). Currently, 1.79% of requests are KO. However, it seems most of these failures are due to local issues or invalid submissions rather than server issues. This requires further investigation and fixes.
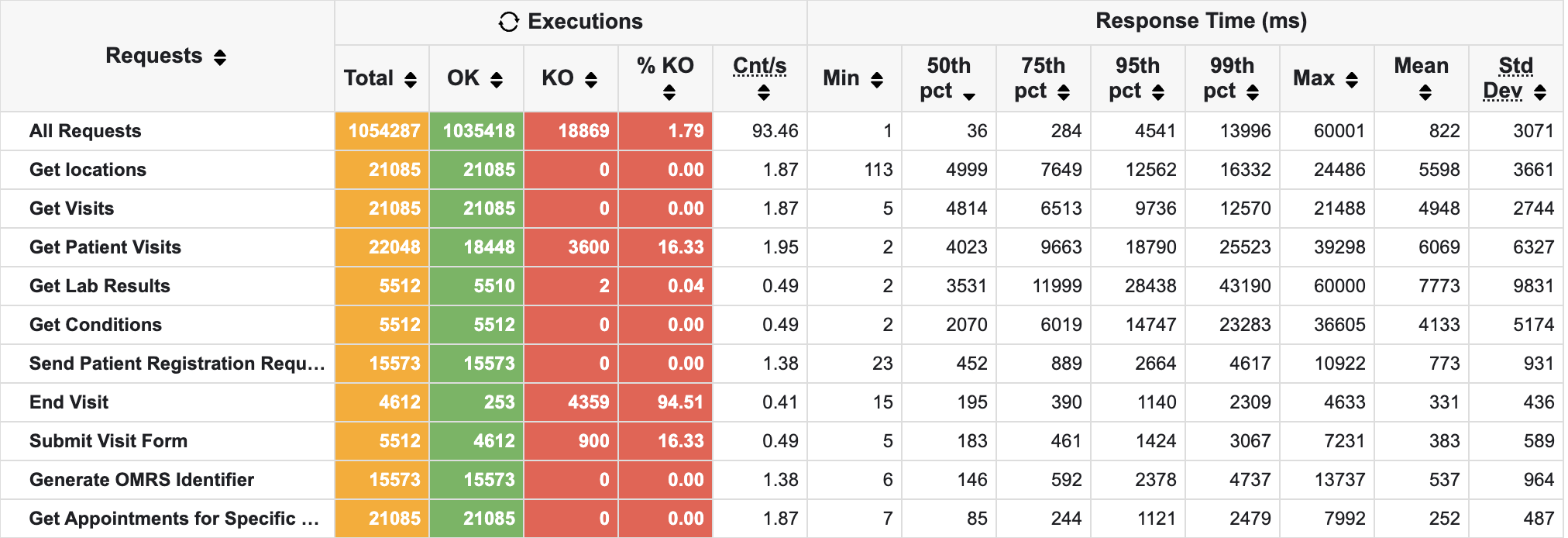
Slowest Endpoints
We also reviewed the slowest endpoints. Here’s a screenshot of the top 10 slowest endpoints:
Location API
Currently, we use the FHIR API to get locations. This API has to make iterative database queries, causing it to be relatively slow. Previously the suggested change was to change to the rest API. But @burke pointed out that switching back to the REST API is just a short-term fix, we should focus on improving the FHIR API to allow more selective data requests. This aligns better with our long-term goal of using the FHIR API extensively and reducing reliance on custom REST API calls.
@ibacher @dkayiwa , please share your thoughts on how to move forward with this endpoint.
Immediate Next Steps
- Me: Investigate and fix the root causes for KOs to ensure accurate tuning and avoid false positives.
- @dkayiwa : Review the report to identify slower endpoints, such as “Get Visits,” (for location, not the visits of a patient) and figure out how to reduce response times. Run tests locally if needed while improving endpoints. I will assist with setting up, running simulations, or updating scenarios as necessary.
cc: @grace @paul @janflowers .