Load testing is a type of performance testing used to examine how a system behaves under significant loads, typically simulating real-world use cases where multiple users access the system simultaneously. The objective is to identify performance bottlenecks and ensure that the software can handle high traffic without compromising functionality or speed.
By examining the testing methodologies of similar systems like Bahmni and assessing various testing tools, the aim is to establish a sustainable and effective testing protocol.
Here’s a summary of findings for OpenMRS load testing, incorporating input from Ian:
A similar setup to OpenMRS is Bahmni, which has its performance tests available here. Bahmni’s strategy involves replaying a series of API calls for two different scenarios: a clinician and a registration clerk. They use Gatling and run on AWS.
For a start, I thought of using three personas: doctor, nurse, and clerk, based on information from this document.
Full Stack vs Backend-Only Testing
A key decision is whether to conduct the load tests on the full stack (UI + backend) or focus solely on the backend:
UI Testing:
- Pros: Reflects users’ experiences more accurately.
- Cons: Requires a web browser, consumes substantial resources, and necessitates more servers for client-layer tests. Frameworks like Selenium and Playwright that drive UI tests are also resource-intensive.
Backend Testing:
- Pros: Simulates a set of API calls based on specific scenarios, providing an efficient way to test backend performance.
- Cons: May not mirror actual workflows accurately. For instance, logging into O3 RefApp involves three calls to the session endpoint, while an API test might simplify this to one call, neglecting important details. Therefore we have to pay extra attention to use all API calls used in the UI.
Given available resources, backend testing seem the most viable solution, led by the platform team, with input from the O3 team to ensure accurate workflows.
Tooling
- JMeter:
- Scripting: Most of the work is done by the GUI. Version control can be challenging, as test plans are often saved as XML files.
- Reporting: Generates detailed reports with a variety of metrics, including response time and error rates. Reports can also be extended with plugins.
- Performance: Can handle a moderate number of concurrent users, but tends to be memory-intensive, especially for larger tests.
- Complexity: extremely complicated to set up, configure, and extract reports from compared to other options. Its GUI can be daunting for new users.
- Gatling:
- Scripting: Can be used with Java for scripting which the community is familiar with (originally it was Scala, but now supports Java as well). Supports version control well, as scripts are text-based and can be managed with Git.
- Reporting: Generates detailed HTML reports with various metrics.
- Performance: Efficient and capable of handling many users with low resource consumption. Designed to support high concurrency.
- Complexity: Very low compared to JMeter. It should be easier because the community (and the platform team) is familiar with Java. Easy to integrate into CI/CD pipelines.
- K6:
- Scripting: Uses JavaScript for scripting, making it accessible for many web developers. Supports version control effectively, as scripts are text-based and can be managed with Git.
- Reporting: Generates detailed HTML reports with various metrics. Can be integrated with monitoring tools like Grafana for detailed reports as well.
- Performance: Highly efficient and designed to handle high user loads with low resource consumption.
- Complexity: Very low compared to JMeter. Should be easier because the community is familiar with Javascript. Easy to integrate into CI/CD pipelines.
- Locust:
- Scripting: Uses Python for scripting, making it accessible for Python developers. Scripts can be managed with Git.
- Performance: Designed to support distributed load testing, allowing it to handle high loads. Its performance depends on the implementation and system configuration.
- Reporting: Offers basic reporting. Can be integrated with monitoring tools like Prometheus and Grafana for detailed insights.
- Complexity: Very low compared to JMeter. However, the community is less familiar with Python. Easy to integrate into CI/CD pipelines.
Given its low complexity, version control compatibility, and use of languages familiar to the OpenMRS community, Gatling stands out as a suitable choice.
Personas
- Clerk
- Nurse
- Doctor
Clerk
Scenario 1:
- Morning Routine:
- Login
- Review calendar
- Check appointments
- Patient Registration
- Load metadata
- Generate openmrs id
- Submit
- Existing patient check-in
- Service Queue Management
- Appointment management
Nurse
Scenario 1:
- Login
- Go to the home page
- Load active visits
- Open a patient from active visits table
- Load patient details
- Load summaries
- Vitals, biometrics, conditions, medications
- Record new information
- Vitals & biometrics
- Immunizations
- Lab Results
- Allergies
Doctor
Scenario 1:
- Login
- Go to the home page
- List all visits
- Open the patient chart
- Load summaries
- Review Medical History
- Vitals & biometrics
- Visit history
- Lab Results
- Conditions
- Allergies
- Record new information
- Notes
- Attachments
- Lab order
- Medication
- Allergies
- Forms → SOAP (Simple) || OPD (complex)
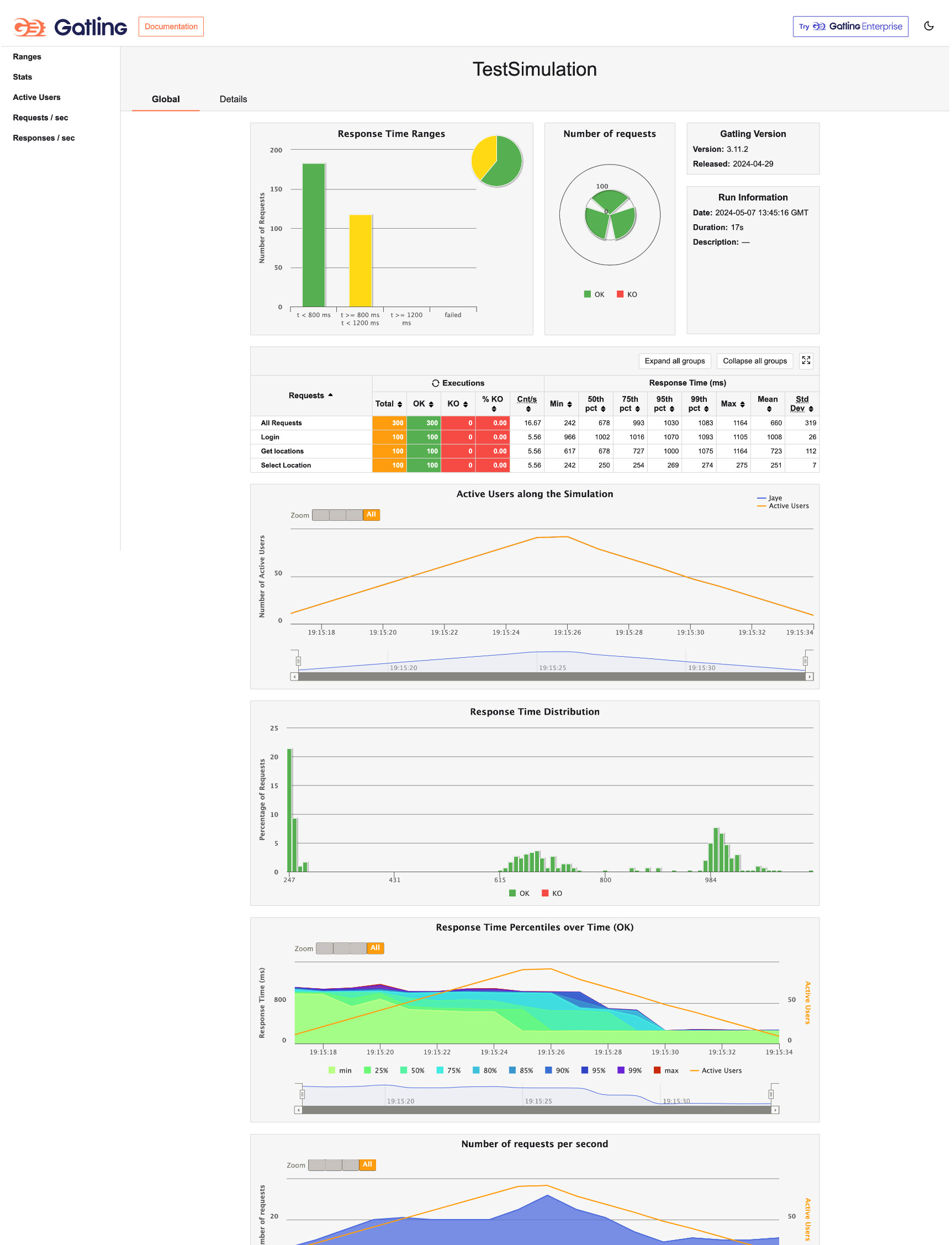
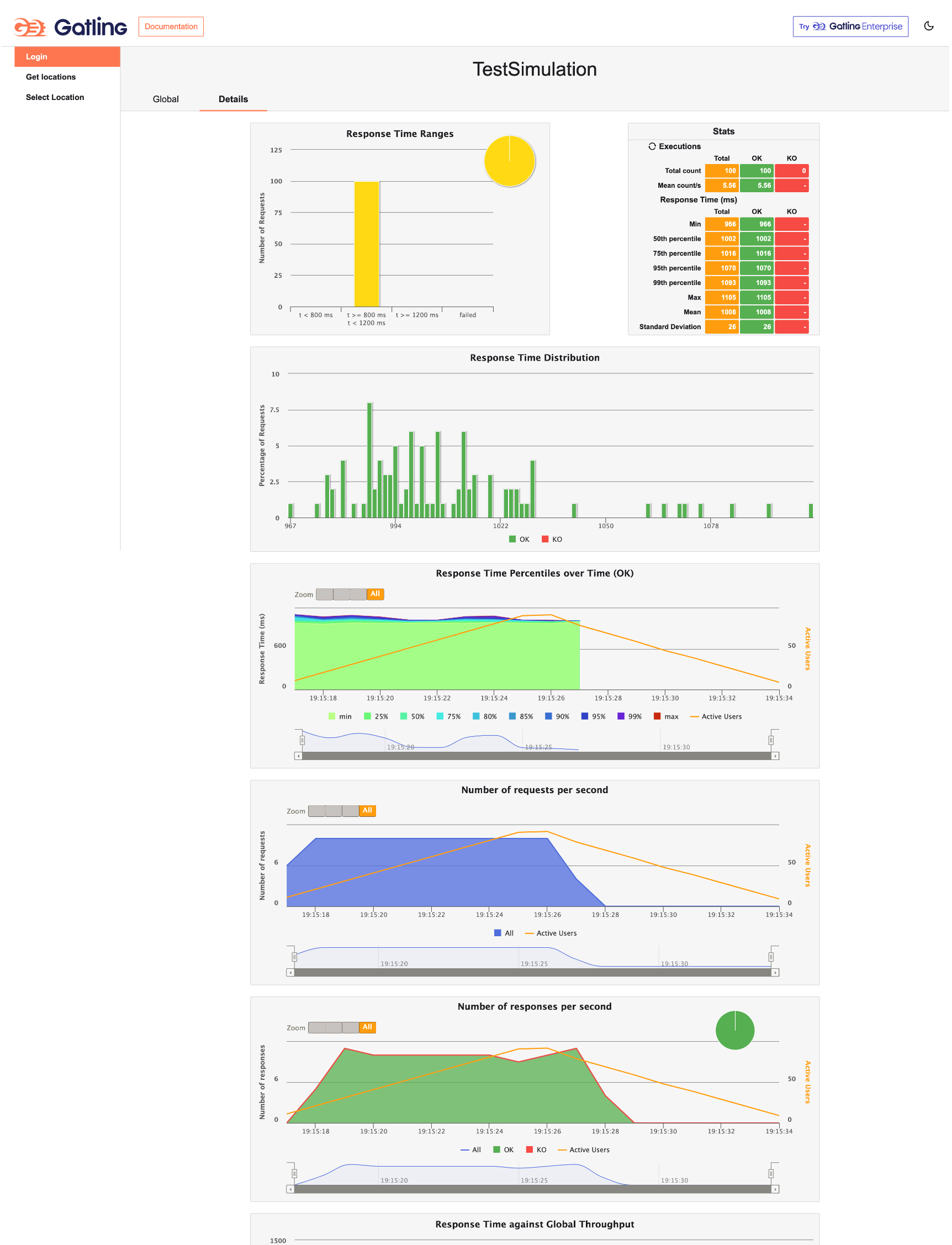
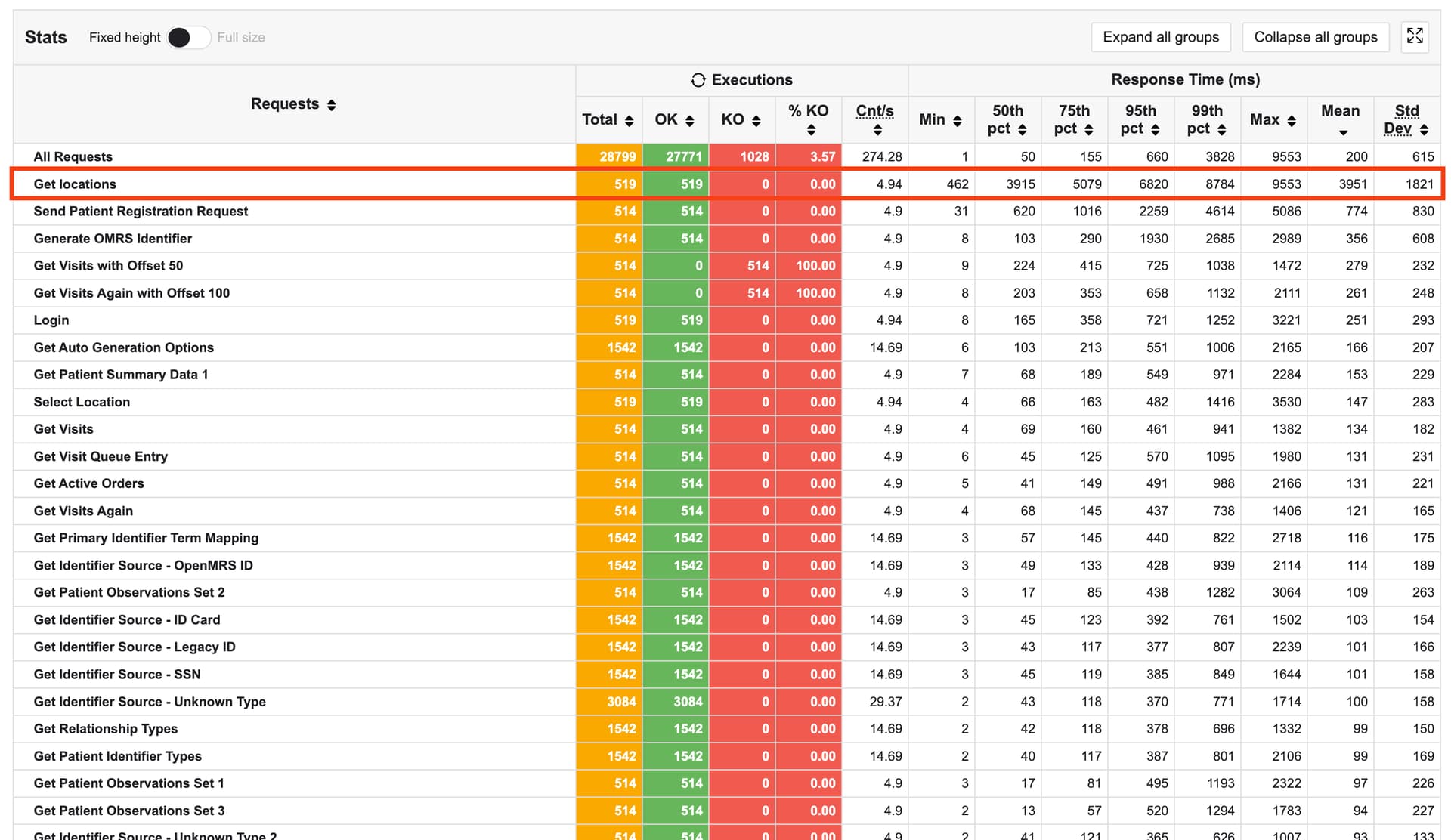
I started a project using Gatling and here’s what the report looks like. This is a small test involving the OpenMRS login, run against dev3.