Am Mutesasira Moses , from Uganda ,Kampala, and i have been actively involved with OpenMRS for three years now.
Am very Excited and happy to join the first OpenMRS felowship 2020/2021 as a fellow mentor in the area of development ,focusing on the PLIR ,FHIR ,Analytics Engine Projects for OpenMRS.
Am glad that i will be working directly with @gcliff as my fellow mentee .
In the first Month (October) of the fellowship ,
i focused on participating in design discussions for PLIR ,FHIR and the Analytics engine and came up with an architectural design approach for the PLIR project ,
Setting up/modifying the wiki page for the project
Getting more familiar with the existing code base for Analytics engine and FHIR projects.
In the second month , we got fellows on board and i have be involved in
Contributing to the development of the Analytics engine and Fhir Project
Having mentorhip sessions with the fellows @ayesh and @gcliff
In My First weeks of the Third Month (December) ,as the OpenMRS fellow Mentor
I Continued to work with the fellows , having mentorship sessions .
I als continued to contribute to the development of the Fhir2 Module , Analytics Engine and the PLIR project .
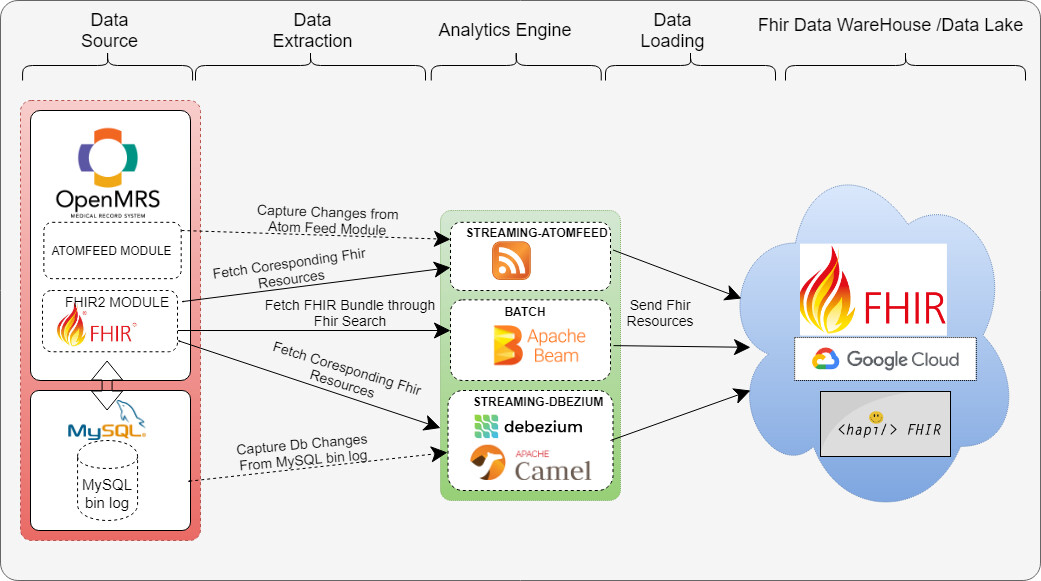
Summarized High Level Overview Of the OpenMRS Analytics Engine
Ive put together a high level design diagram of the OpenMRS analytics Engine Pipeline below to give a summarized overview of how the different component work together
In the above design Diagram , OpenMRS is the data Source . The FHIR2 modules does the work of translating OpenMRS data models into FHIR data for easy Interoperability with external Systems.
Analytics Engine
The Analytics Engine does the work of Extracting data from OpenMRS and Loading it to an external System.The Anaytics Engine Component is basically subdivded into three sub-components (sub-modules)
Batch . This extracts Fhir Data from OpenMRS in Bulk in from of Fhir Bundles using Fhir Search and depends on Apache Beam to export it to an external component.THis is meant for Batch/Bulk processing
Streaming-Atomfeed. This coponent continuously listens to changes from the OpenMRS atomfeed module, extracts the resource uuid from the feed and fetch the corresponding Fhir resource from OpenMRS .Note that this can only listen to changes made with in the Application .This is meant for Streaming processing.
Streaming-Dbezium. This component continuously listens to changes from MySQL bin-log , extract the table uuids from the logs and fetch the coresponding Fhir Resource from MySQL and export it to an external server . This has an advantage over the
Streaming-Atomfeed that it can capture changes made directly to the DB outside of the OpenMRS Application . At the heart of this sub-module is Apache Camel and an Embedded Dbezium Engine . This is also meant for Streaming-Processing.
Fhir Data Ware House
After data is extracted and loaded into an external system from Various OpenMRS sources , A Fhir data ware House is formed where Advanced Analytics tools like Elasticsearch , Apache Spark, and Apache Kafkacan be used to perform Big Data Analysis.
Several Data ware Houses are supported by the Analytics engine including Google Cloud Platform , Any Generic Fhir Server like Hapi Fhir Server , and Parquet files generation
in the previous weeks ,
i have majorly focused on development around the HAPI-FHIR server , and studying different behaviors of how data is persisted in there. see my Talk Post here .
I have basically been working on supporting the collect_data_operation with in the HAPI-SERVER, so that it can process the Measure resource to extract the data that would be necessary for the calculation of the TX_PVLS indicator , and Dockerising HAPI-server instances for PLIR intergration
For the previous weeks ,
My Focuss has been around the Analytics Engine development , debugging ,testing and Fixing Bugs so that we prepare for first deployment at AMPATH.
I have also been having session with the Inteslisoft (BAHMNI) team to test out the the Analytics Engine against Bahmni for the PLIR project.
I also continued having mentorship session with @gcliff and reviewing PRs.
I built out sample CQL Libraries for the calculation of TX_PVLS indicator and also Updated the FHIR measure resource to be able to generate the Measure Report Out Put for the TX_PVLS indicator results.
I also continued sessions mentorship with @gcliff , reviewing PRs and also contributing to the analytic engine
For the Past weeks , ive been working on the Analytics engine to ensure it intergrates well with Bahmni ,and also finishing up the CQL indicator LIbrary.
I have also worked with the infra-team to finalize setting up the remote instances for PLIR POC and also continuing mentorship with @gcliff
For the next week , ill focus creating a qa-framework for the PLIR integration setup
For the Last weeks of March ,
I have been working on pre-configuring and dockering all the components for the PLIR project for easy locall deployment . see the dockerised setup .
I have also been improving the PLIR project wiki pages for clear instructions on how to set up the project and testing out all the CQL integration .
I have also been working with the infra team to set up remote demo instances for the project ,and also continued contributing to the development of the FHIR module and the Analytics engine component, reviewing Prs and mentorship session with @gcliff and also attebded calls and mentorship sessions with @jennifer
I also continued working with the PLIR bahmni team for intergrating the Analytics component with Bahmni
In the next quater , i shall be focussing on QA with in the FHIR/PLIR project together with the QA-team .
For the past weeks , i have been looking and analyzing different approches to have Automation Tests for PLIR . these included writing bash scrips , Selenium ,etc .
Finally we opted for the HIE-automation-test framework ,built on python behave ,since it best fits with in a typical HIE-system .
I did initial work to extend the framework to support the basic PLIR work flow ie
Post Obs data into OpenMRS
Track the transactions in OpenHIM
Check whether the correct TX_PVLS indicator measureScore was calculated in HAPI FHIR
The Instant OpenHIE project aims to reduce the costs and skills required for software developers to deploy an OpenHIE architecture for quicker initial solution testing and as a starting point for faster production implementation and customization .
For the past few days , i have been looking into how we can make use of this and how we can easily plugin OpenMRS into an InstantHIE docker setup .
I also did more work around the HIE-Automation Framework , making most testing parameters configurable and easily re-usable for Testing any other Indicator CQL based Calculation other than TX_PVLS .
I Continued Having weekly mentorship sessions with my mentee @gcliff
As we are wrapping up the PLIR project ,
My focus has been around improving the PLIR project technical documentation .
We also decided to add one more indicator TX_CURR ( Number of adults and children currently receiving antiretroviral therapy )as an extra POC CQL based indicator calculation in addition to TX_PVLS.
we will have our fellow @gcliff ,define the CQL logic and all the CQL related resources for TX_CULL Calculation in a typical HIE setup.
Next month Month i will set up a mini-sprint to get all the work related to TX_CULL CQL based calculation done , where we will have @gcliff do the CQL definition.
i will also focuss on creating a non Technical documentation for the PLIR project
As we are wrapping up the PLIR project ,
I would like to thank my mentors @k.joseph and @ibacher for their wonderful Technical Guidance.
I would also want to thank @jennifer and @grace for their wonderful Project management work .
Ive created the Slide deck and Video Presentation Below Summarizing all My work during My Fellowship Journey .