For your information, this is a follow-up from the thread that began here: Expanded cohort and delta synchronization proposal and concluded with Ada’s final message. Briefly, we have decided to consolidate all of the features of the expanded cohort module into the reporting compatibility module. This will enable us to implement the delta synchronization for the expanded cohort.
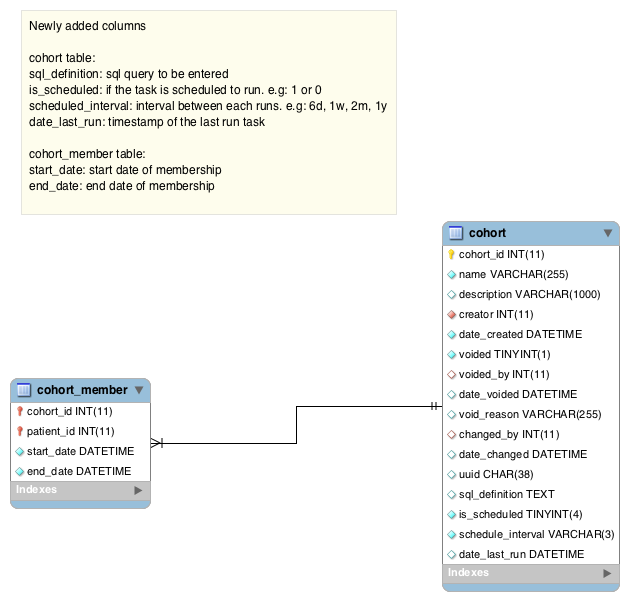
After going through the paces of understanding the code and procuring the requirements for my project. I have come to realize that I need to come up with a revised data model for the cohort definition particularly in openmrs-core that houses two tables: cohort and cohort_member.
The attributes sql_definition, scheduled_interval etc. seem to be more metadata than data.
Maybe you need a cohort_definition table for them?
Also instead of the scheduled_interval you can use a TaskDefinition.
Agreed. sql_definition assumes the definition will be in SQL. I’d suggest, per Darius’ suggestion, we use handler (fully specified classname of Class in charge of calculating the cohort), handler_config (any configuration needed for the handler), and handler_data (a place for a handler to persist any metadata like data about when the cohort should be run again). If you only want to handle SQL-based definitions, then you can write a SQL handler and then use it in all of your cases.
Alternatively, if you want to use sql_definition, then put it into your module-specific table and not directly into the cohort table, since we will not want this design in core.
Also, cohort is meant to serve as the base that handles both static (manually defined) and dynamic (calculated) cohorts. Initially, I had imagined we would keep the cohort table limited to those attributes shared by all types of cohorts and any static- or dynamic-specific attributes (like definitions & scheduling) would go into cohort_static and cohort_dynamic tables extending the cohort table. I realize this could be over-designing (which I tend to do), so I was okay with having a few dynamic-specific attributes in the cohort table that would go unused for static cohorts.
As for scheduling, we should not assume only intervals for scheduling as your approach of a 3-character schedule_interval suggests. We would also want, for example, to support recalculating a cohort every Thursday at 21:00 GMT+3. Rather than trying to come up with a model to handle all possible scheduling needs, my advice would be to leave this up to the handler to manage and simply put a date_to_expire attribute on the cohort (if exceeded, the API knows the cohort is stale).
As Ada pointed out, this isn’t the planned GSoC project, so you can do this work wherever you see fit. We do plan to add start_date and end_date to the cohort_member table in core, so, if you do the same, it will be easy to transition when these are supplied by core.
Agreed. This is an argument for separating dynamic cohorts (those that are calculated) from the base cohort, since cohorts are data and the definitions of dynamic cohorts are metadata.
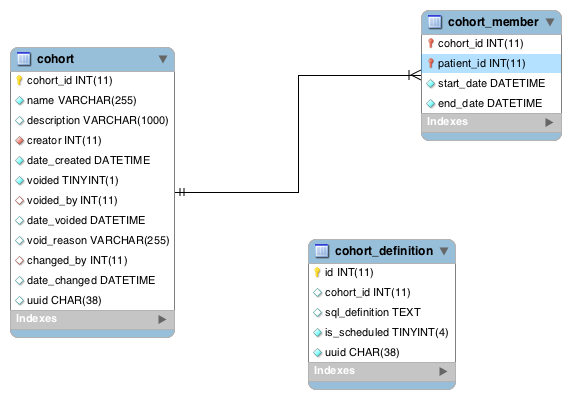
Thank you Burke. It took me a while to discuss with my peer group. As I understand, we are maintaining cohort table as before. While the dynamic metadata of cohort will remain in a separate table cohort_definition or dynamic_cohort.
I drew up an ER model, and I quite can’t understand the relationship cohort and cohort_definition table should have. Should they have a identifying or non-identifying 1:1 relationship?
Secondly, as you and Darius suggested, the recommended approach to cohort calculation is the handler. I tried looking up resources to see how the handler works in OpenMRS. Are these among the only resources available?
API Save Handlers - Documentation - OpenMRS Wiki (example here is not accessible). I will appreciate if you mind sharing the best resources to understand handler?
Correct me, if I am wrong in anyway. I hope to see that I’m on the same page as rest of the community.
My recollection of that call is that we ultimately were leaning towards something a bit different from “simple approach”. Thinking out loud, I would do it this way:
interface CohortHandler {
/** implementations should decide whether to recalculate membership for the cohort, based on cohort details
* like last run timestamp, ttl, etc. After this, the implementation should save any changes made.
* return whether or not the cohort was recalculated
*/
boolean maybeUpdateMembers(Cohort, CohortService)
}
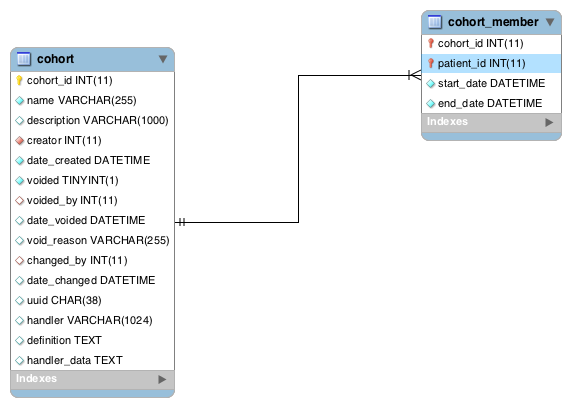
Then add these columns to cohort:
handler (varchar 1024)
this is a fully-qualified java classname of an implementation of CohortHandler
definition (text)
contents defined by handler (API treats as a black box & gives/gets from/to handler)
handler_data (text)
handler can store whatever it wants here, e.g. a last calculation timestamp, a ttl, or some more complex JSON
And there would be a scheduled task that periodically calls CohortHandler.maybeUpdateMembers for all cohorts in the database.
(Maybe a null value for cohort.handler means it’s a non-dynamic cohort whose membership is manually managed. Alternately we need a ManualCohortHandler implements CohortHandler for this case.)
To answer your specific question about handlers, it’s not like SaveHandler, or anything called “Handler” in the OpenMRS API now. This would be a new thing.
What exactly are the contents are we talking of? Is this where, for example, a sql definition forms one of the many different content the handler defines?
Taking down your suggestions, I have revised the ER model:
Again, this comes back to Burke’s call of wanting this change in core? Is it safe to assume that I can proceed with this?
After discussing with my Professor, owing to my project being purely for academics in this case my Masters program, we feel that contributing to openmrs-core might bring some unforeseen dependencies for this moment. Instead, we provide a solution that is very much self-contained (in a module) and that can enable an easy transition into a desired design specification that is planned for openmrs-core.
Supposedly for example, if I provide the necessary changes in the reporting compatibility module, can you suggest how I should proceed with it? There shouldn’t be a conflict of interest in terms of development and I’m open to suggestions on how I should go forth implementing the necessary modifications that would enable an easy transition in the future?
@vshankar, honestly I think that the most straightforward path is for you to make these changes directly in a branch (in your github account) off of the master branch of openmrs-core. That way, since you’re in a branch you’re not going to be affected by other changes in openmrs-core. And the merge should probably be straightforward in the future, since nobody else is really touching that part of the code.
However if you do want to do this in a module I would recommend creating a brand new “cohort” module, rather than trying to put this in an existing module that it doesn’t belong in. Doing this in a module will add a small additional bit of complexity because while it’s possible to extend a core OpenMRS table and domain object in a module, it’s a bit tedious to do this.
Thanks @darius. There is already an expanded cohort module that was using a table with the sql definition for dynamic cohorts. We have decided to refactor this module instead.
Correct me if I am wrong, is creating a table cohort_definition with the following columns a way to go forward:
cohort_id INT
handler VARCHAR
definition TEXT
handler_data TEXT
Is it wise to add the membership information (start_date, end_date) to this table? How do I go about this?
Yes, the idea is that you’d create a cohort_definition table that effectively extends the cohort table with the additional columns being discussed.
Note that start date and end date refer to the cohort_member table, not to the cohort/cohort_definition tables.
(Actually, making that change in a module may be a little complicated, since it also requires dropping a unique constraint from the core cohort table.)
Do you suggest I make enforce the change in cohort_member table itself to avoid this complication?? I will be willing to do that instead of jumping through hoops to achieve it.
Well, my suggestion is that you should do this work in a branch of openmrs-core, since I think that’s the most straightforward, and least likely to run into other dependencies.
If you’re doing this in a module, I guess that nothing prevents you from dropping a constraint on a table that’s in core, though any core code that references the table may break as a result. And in a module, to change the way that cohorts work you may have to jump through the hoops at the Extending a Table Through a Module wiki page.