It looks like the Parent-Child relationship would assume that there is only one server that a child would sync from? What about the case of an independent Client Registry that is FHIR compliant? Would you sync the non-patient resources with the parent and then (for both the parent and children) sync patient resources with the Client Registry? (Same question for a Facility Registry or Health Worker Registry using mCSD). tl;dr you may want to have the option to have multiple FHIR servers for syncing different resources.
As an FYI, there is an OpenHIM FHIR sync meditator (STU3) for practitioners https://github.com/openhie/openhim-mediator-fhir-sync which maybe could be extended to help manage your FHIR sync process(es) by providing a nice UI for periodicity of syncs and providing audit logs (e.g. ATNA). Not sure if @rcrichton knows of any similar mediators already in existence.
@raff@dkayiwa Yes we are looking to be able to bring data from different facility level installations together in a single location, hence keeping an eye on this project. Initially we tried Sync 1.0 which did not work too well
@raff yes I would like a working sync module on 2.x, I’m currently stuck on 1.9.8 as it is the last version the sync module works without major problems, and will not update to more recent versions as they don’t support it, and it is critical to my implementations.
@aramirez would you be able to test out this new Sync 2.0 work, over the course of the next 2 months, and provide feedback?
This doesn’t have to be on production data (obviously it wouldn’t be as you can’t upgrade until you have a working sync on 2.x) but you and/or your team would need to spend the time/resources to test out the new sync modules against an upgraded copy of your implementation.
@ssmusoke, @slubwama, @jmpango, are you in a position to test out this new sync code across a small number of facilities, and provide feedback and/or bug reports?
And could you do this within the next couple months?
in this sprint, we would like to provide the possibility to pull an object from Parent and persist them in the Child instance. For this, we need FHIR and AtomFeed latest snapshots and there is the question:
Would we like to deploy snapshots on Nexus server or store these modules in the Travis cache?
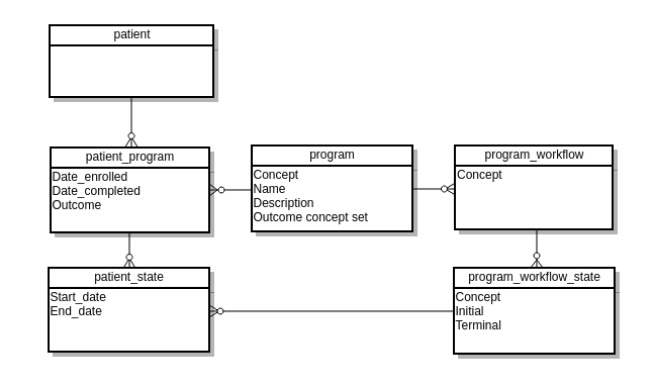
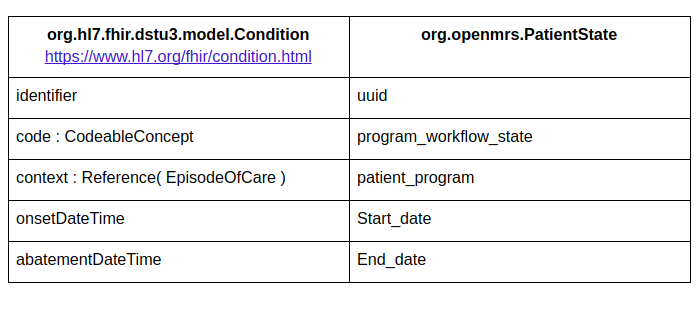
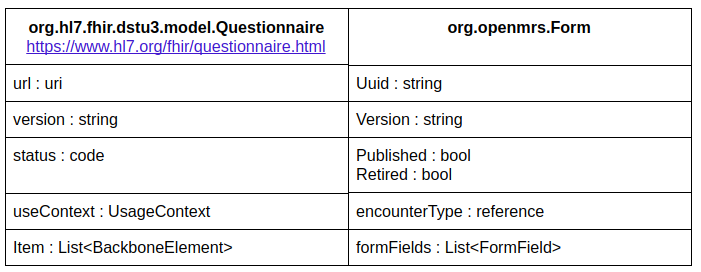
there appears some ambiguity in implementing FHIR strategies from scratch. More precisely, we’ve problems with mapping Patient State and Form. I attached our proposition below:
The Program resource in OpenMRS is designed to track patients in a treatment program or study protocol, where patients are typically enrolled and then may travel through different states until they either complete the program, are transferred out, or lost to follow up. FHIR’s Condition resource, on the other hand, are designed to track problems in a patient’s problem list. Therefore, I do not think PatientState (a state within a treatment program or study protocol) would map to FHIR’s Condition. I would think our Program would map more closely to FHIR’s Protocol, which I believe has been subsumed into PlanDefinition. From my understanding FHIR’s PlanDefinition is used to define protocols (like our treatment programs), which would presumably include the metadata of available states. In FHIR, the actual data about progress of a specific patient through a PlanDefinition is recorded in CarePlan and associated resources. So, presumably, our PatientState (which is data about a patient’s current status in a “protocol”) would map somewhere close to CarePlan, Activity, or Detail. @jteich has put a lot of thought into care plans in OpenMRS, so may have insights. My impression is that this may not map neatly to FHIR and the CarePlan resources are relatively immature in FHIR, so it may not be worth the effort to map to FHIR at this time.
You are correct that OpenMRS’ Form would map to FHIR’s Questionnaire; however, there are some significant differences in the use of these resources at this time that might cause problems. @darius and I discussed this on today’s design forum. FHIR’s Questionnaire and QuestionnaireResponse resources are designed primarily to capture any data from a patient. In OpenMRS, the primary use of forms is for encounter forms, where the majority of the data collected are discrete, clinical data (i.e., Observations). So, we need a way to define our forms as FHIR questionnaires where the items are answered with an observation. The list of possible types for Questionnaire→Item.type doesn’t seem to include observation as an option. @darius’ suggestion was to not try to map forms to FHIR right now (just use our REST representation)… he may be right. It’s close; however, I don’t think a model where all responses to forms are expected to be QuestionnaireResponses (instead of Observations) will work well for us.
I took sometime to look at the code in the new atom feed module developed as part of these efforts, the code looks great, good job guys! I just have a few things I would like to comment about and some questions.
Why is there a hibernate interceptor in the atom feed module? My assumption was that it would be in the sync 2.0 module and the atom feed module would subscribe and listen for events from it, otherwise what would be the purpose of the sync 2 module?
I noticed that the feed writer attempts to write the events as they come in to the DB always through a new transaction that is provided by a custom transaction manager, why did you have to do this? Is it good to have 2 transaction managers within the same application context? I also noticed that the EventService instance isn’t a spring bean, could possibly be what drove you into adding a custom transaction manager since spring can’t wrap transaction advice around the methods of a non spring managed bean. If you got rid of the custom transaction management, make EventService a transactional spring bean with the propagation attribute set to REQUERES_NEW, you would achieve the same behavior.
Where is the git repo for the openmrs-atomfeed-common dependency? So I can look at the custom transaction manager implementation? May be I will get a better undestanding of why it’s necessary to have it.
@wyclif, my understanding from earlier conversations with @SolDevelo was that the Interceptor in the Atom Feed module was a temporary solution that they intended to remove. However, the idea was not that this should go into the sync module, but that it is already implemented in the Event module and that the Atom Feed module should be subscribing to events published by the Event module. Am I misunderstanding?
(But I think it’s underspecified to actually be ready-for-work; we had a long discussion about this starting from message 38 of this thread about what to do with the event module, but didn’t settle on an answer.)
According to your suggestions we will avoid mapping OpenMRS Form and Program to FHIR, for now. However, we will have more questions about mapping in the near future. There is a list of FHIR resources that we planned to map - link. Some of this resources will need to have resolved an ambiguity.
Just like @darius and @mseaton said. We pushed Hibernate Interceptor logic there temporarily. It is because the concrete decision about what we should do with events is not established yet. Additionally, we did not to want to block work progress.
This was implemented by @dserkowski and I do not remember issues with default transaction manager well. I will answer this soon.
Thanks guy for your replies, now I understand the reason for having the interceptor in the atom feed module. I’m not sure we want to change how the event module fires events since that would break any existing modules dependent on it but that’s a topic for another day. So what would be the role of the sync 2 module in case atom feed module is changed to depend on the event module?
@pkornowski probably I shouldn’t be adding code comments here but I didn’t know anywhere else to add them, I looked at the transaction manager in the atom feed common project, it has another dependency that I had to look up and noticed the reason for having the custom transaction manager boils down to just being able to turn off auto commit on the underlying jdbc connection and due to this there is a lot of somewhat other hacky code in its implementation, may be best to encapsulate the writer’s logic in a service method that has a hibernate DAO object so that you can use the sessionFactory.getCurrentSession().setFlushMode() method and then get rid of the custom transaction manager.