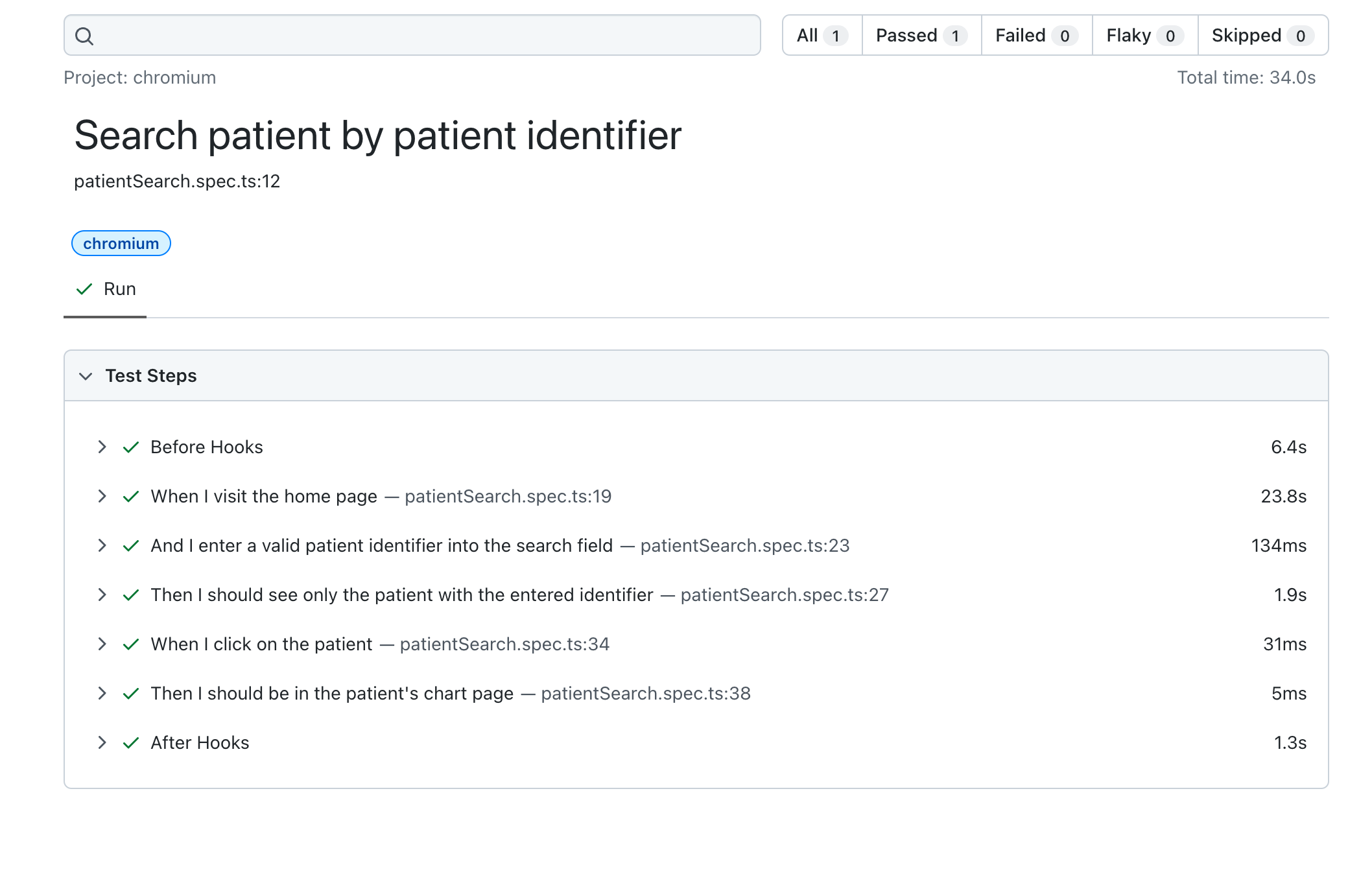
I’m excited to share some proposed improvements to our end-to-end (E2E) testing strategy. Our goal is to enhance test readability and maintainability, making it easier for both non-technical stakeholders and future developers to understand our test coverage.
In response to recent requirements from our funders (WHO and Digital Square), we need to include some form of BDD human-readable text in our test coverage. We also want to ensure that the tests we create are easy to maintain and understand by future developers.
After considering our options, I suggest using test.step from Playwright to meet these requirements. It is important to note that Playwright does not natively support BDD or Gherkin. We would need to use third-party libraries to integrate Gherkin, which may add complexity compared to using only Playwright’s built-in features. This approach adds a layer of abstraction, potentially making it harder to access some existing features or functionality introduced in future Playwright releases. We might need to wait for the third-party libraries to be updated to support new Playwright features or find alternative ways to implement them within the context of the BDD framework. We faced similar issues with our previous Cypress setup, and limited documentation might also be a concern.
To demonstrate, here is an example of how the code would look using test.step:
I plan to use Gherkin-like step definitions, especially the “I” keyword, to create a more user-centric focus on actions and experiences. This approach can help the team empathize with the end-user and understand their perspective. For example:
When I visit the home page
And I enter a valid patient identifier into the search field
I kindly ask for your feedback on this proposed approach. Are there any concerns or suggestions you may have? I value your input and appreciate your support in enhancing the quality of OpenMRS E2E testing.
Thank you for your time and consideration, and I look forward to hearing your thoughts.
Do you mind giving some more details of what the non-technical stakeholders want to understand about test coverage? Are they just looking for coverage percentage? (50%, 60%, etc?). Or are they interested in simply understanding what features are being tested? (Patient registration, Record vitals, Allergies, etc?). Or is it something else?
For all the time we used Gherkin, i have never seen any single non technical person looking at it. So clearly understanding what they need will help you avoid falling into the trap of wasting time incorporating what they do not actually need to answer their practical questions.
Thanks @dkayiwa for your insightful response. As per my understanding, the requirement is to help non-technical people understand the steps in each test and also to help them figure out what is broken in an end-to-end test. The intention is to ensure that the tests are not only clear and concise for developers but also approachable for non-technical stakeholders (including @grace , @suruchi ), making it easier for them to grasp the test coverage and pinpoint issues when needed.
I’m in favour of this change. Even if non-technical people don’t ever look at it, I find our current e2e testing opaque when things fail—and the most important thing tests can do is catch failures and help us diagnose why they failed (What was the test doing? What was it trying to test? What did the code actually do instead?).
The problem with Cucumber / Gherkin, at least from my perspective, is that it added a layer of indirection that slowed the velocity of writing and executing tests, whereas having properly identified steps in the code is straight-forward and also helps answer the question “what is this line of code actually trying to test?”, i.e., I read it as basically a system of enforced commenting (which is a good thing!).
test('should be able to search patients by identifier', async ({ page }) => {
// extract details from the created patient
const openmrsIdentifier = patient.identifiers[0].display.split('=')[1].trim();
const firstName = patient.person.display.split(' ')[0];
const lastName = patient.person.display.split(' ')[1];
const homePage = new HomePage(page);
await homePage.goto();
await homePage.searchPatient(openmrsIdentifier);
await expect(homePage.floatingSearchResultsContainer()).toHaveText(/1 search result/);
await expect(homePage.floatingSearchResultsContainer()).toHaveText(new RegExp(firstName));
await expect(homePage.floatingSearchResultsContainer()).toHaveText(new RegExp(lastName));
await homePage.clickOnPatientResult(firstName);
await expect(homePage.page).toHaveURL(
`${process.env.E2E_BASE_URL}/spa/patient/${patient.uuid}/chart/Patient Summary`,
);
});
The changes @jayasanka proposes are basically adding those test.step() instructions with things like:
await test.step('Then I should see only the patient with the entered identifier', async () => {
await expect(homePage.floatingSearchResultsContainer()).toHaveText(/1 search result/);
await expect(homePage.floatingSearchResultsContainer()).toHaveText(new RegExp(firstName));
await expect(homePage.floatingSearchResultsContainer()).toHaveText(new RegExp(lastName));
}
Now if that fails, the test step will show a red X (I’m presuming), but when I look at the underlying test code, it helps clarify what those expect statements are actually trying to check for. There are a lot of reasons the test might fail (maybe the floatingSearchResultsContainer() got moved in the DOM; maybe the translation strings got changed; etc.) but I find having that clarification of the intention of the specifications useful.
Using test.step is a very elegant approach to solving this problem. I especially like how changes to existing tests will be minimal and that it appears we can avoid using external libraries. We should probably document what the recommended Gherkin syntax looks like and find an approach to enforce it in the future if this becomes the approach that we coalesce around. Happy to help in any regard. Thanks!
I love this approach. It helps me to ensure that I’m mimicking the user behaviour on an E2E test which is exactly the goal of a E2E test. Since we are already comments on the test snippets this is not a new thing as well.