We’ve been hearing for quite some time now from people (including me) complaining about the OpenMRS startup time. We’d love to do something about it.
I’ve taken some time to do an analysis and come up with recommendations so we are clear on possible outcomes.
The tests were conducted on the hardware with Apple M1, 16 GB of RAM allocated for Docker Desktop and SSD running ‘docker compose up’ from https://github.com/openmrs/openmrs-distro-referenceapplication/tree/3.x-core-2.8 that is OpenMRS O3, which is based on OpenMRS core 2.8.x and 28 modules. The base core image is running on JDK 8 and Tomcat 9.
To start with I measured the startup time with an initial setup (db schema and demo data creation), which was 8 minutes 29s. The consecutive startup times are much lower and we’ll be investigating them going further.
Based on the startup logs, the entire startup process took 45.8 seconds. A number of debug messages were added to measure time at different stages.
On more modest hardware it can be significantly slower. In addition the startup time can be affected by e.g. custom modules (additional Liquibase scripts, module initialisation methods, known circular dependency issue, see TRUNK-6421) and extra import data to process (via Initializer).
The startup was performed across multiple containers (db-1, backend-1, gateway-1, frontend-1), with the majority of the application logic and initialization occurring within the backend-1 container.
Logs Analysis
Here is a breakdown of the time taken by the main high-level steps:
| Startup Phase | Duration | Details |
|---|---|---|
| 1. Infrastructure Initialization | 1.000 s | Time until the MariaDB database (db:3306) was available to the application backend. |
| 2. Tomcat Bootstrap | 1.402 s | Time from DB readiness until the Tomcat server component began its initialization process. |
| 3. Web Application & Spring Context Initialization | 11.444 s | Time from Tomcat start until the Spring Web Application Context (WAC) was completely refreshed and initialized. |
| 4. Module Startup | 31.949 s | Time taken for all 28 modules to be loaded, processed and initialized. |
Looking at logs we can also tell that refreshing application context happens twice. The first time is without any modules in the 3rd stage, which takes ~5s and the second time is with modules in the 4th stage, which takes ~22s.
Also in the 3rd stage, we run Liquibase checks, which take 5s.
Profiler analysis
Further analysis with a profiler allows us to break-down stages. We’ll be using YourKit profiler connected to Docker agent. Please note the timings are different with a profiler as profiler sampling slows down the process resulting in the total startup time being 143s instead of 46s. The timings from the profiler can be divided by 3.
Here’s a list of the most time consuming methods ordered by time spent in them alone (not including child calls) (2nd column):
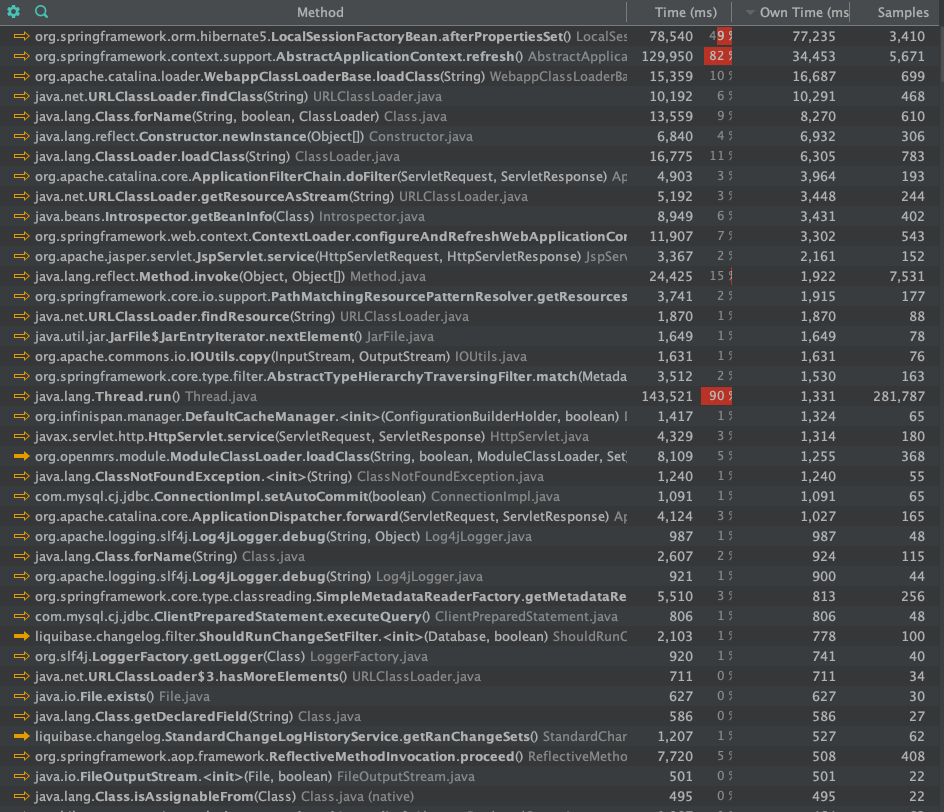
It confirms that refreshing application context contributes greatly to the startup time (130s of 143s total). It consists of Hibernate session creation taking 77s, creation of Spring context taking 34s and the rest being mostly class loading 19s.
The next big contributor is ClassLoading. The time spent in class loaders alone is ~48s (summing up loadClass, forName, findClass, getResourceAsStream, findResource methods own execution time). Much of the class loading happens during refreshing application context.
Recommendations
If we want to make significant improvements to the startup time, we shall:
-
Implement startup performance test to measure improvements
-
Switch default image from JDK 8 to JDK 17, which speeds up startup by 10s, 22% speed up (thanks to improved class loading).
-
Do not run Liquibase checks on each startup, which speeds up startup by 5s, 11% speed up, see TRUNK-6418
-
Eliminate the need to refresh Spring application context twice (or parts of it), which should save us at least 5s, which is 11% speed up.
-
Optimise module loading, which should give us at least 10% speed up.
-
Do not expand jars on each startup, but keep them expanded between restarts instead
-
Optimise class loader methods with caching
-
-
Issue startup warnings if module mixes annotations and xml declared services (slows down startup time by 10 times, see TRUNK-6363)
-
Implement partial reload of jars and Spring context similar to Spring Boot during development with even 50% speed up when hot-deploying Java code changes, see Spring devtools.
If we want to improve the initial setup of O3 we shall:
-
Generate demo data at build time and import ready to use demo data set at runtime, which gives us back 4 minutes 28s, 52% speed up compared to the total startup time with initial setup of 8 minutes 29s.
-
In clustered environments we shall not run data imports on each node rather use a single node to do imports, see TRUNK-6418, reduced new node setup time by at least 2 minutes 47s
All this work can be followed at TRUNK-6417.
Please let me know if you have any questions, comments or see other possibilities for improvements.