I tried to restore database from one server to another after restore I am getting this error , But the Server from which I took backup is working fine there is no error on that. I am using V 0.90
I tried to restore database from one server to another after restore I am getting this error , But the Server from which I took backup is working fine there is no error on that. I am using V 0.90
Please look into /var/log/openmrs/openmrs.log and try to find out which migration is causing the error and why? check into database (dbchangelog), once you have identified the specific migration - for the checksum.
What command did you use to take the backup? It seems from the error message that some tables are missing from the backup.
Hi @darius
1)bahmni -i local backup --backup_type=db --options=openmrs is the command that I have used for taking backup.
2)After the backup, I copied the relevant file to our other server in /data/openmrs folder and also changed backup_info.txt to include the new backup pointer and used the following command to restore: bahmni -i local restore --restore_type=db --options=openmrs --strategy=pitr --restore_point=20180307003023_full.
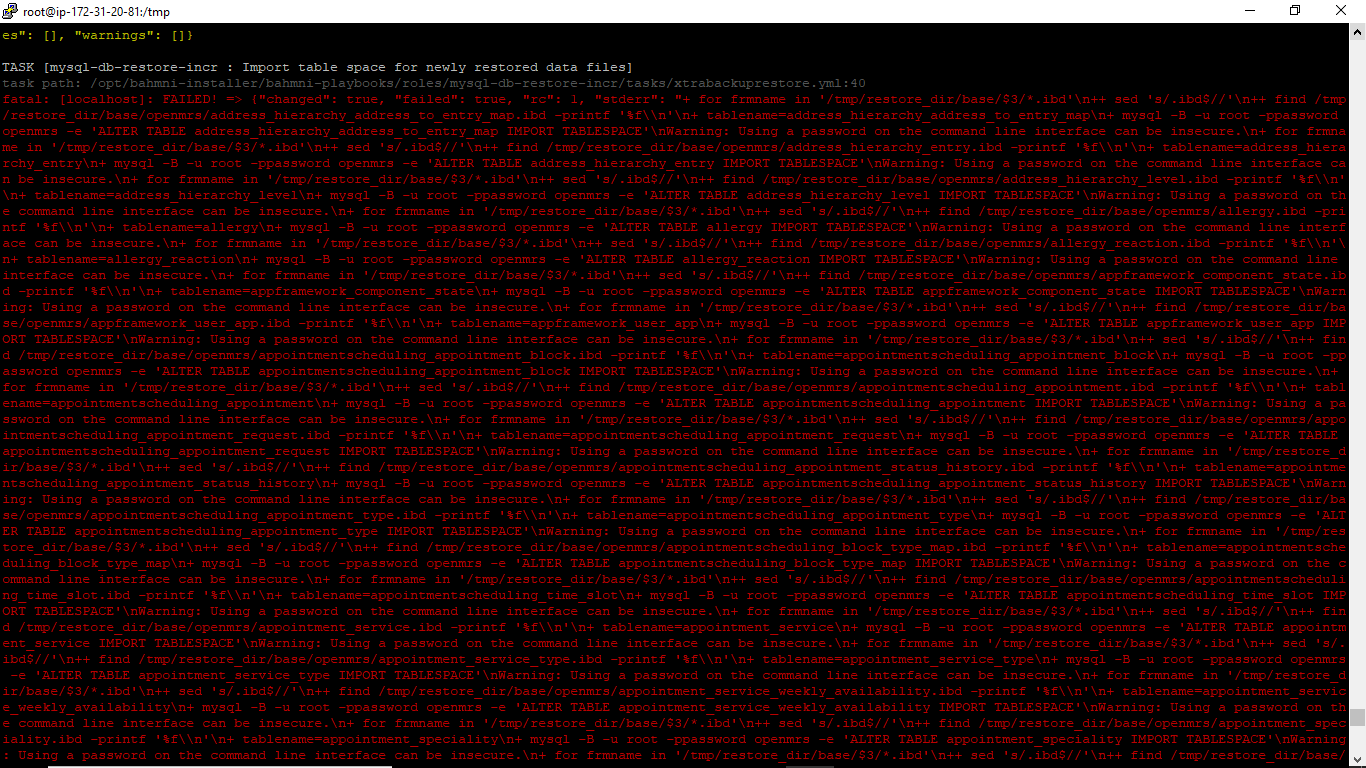
3)The restore command runs successfully till the point - “Import table space for newly created data files” and it throws error on screen
4)The /var/log/backrest/mysql_backrest.log file has only this information:
20180307-00:39:26 STARTED : Restore using xtrabackup /data/openmrs//20180307003023_full 20180307-00:45:30 STARTED : Restore using xtrabackup /data/openmrs//20180307003023_full
5)The /var/log/mysqld.log file has series of these statements for almost all the tables: 2018-03-07 00:45:46 30893 [Note] InnoDB: DISCARD flag set for table ‘“openmrs”.“DATABASECHANGELOG”’, ignored. Followed by series of these statements for almost all tables: 2018-03-07 00:45:47 30893 [Warning] InnoDB: Table ‘“openmrs”.“address_hierarchy_address_to_entry_map”’ tablespace is set as discarded. 2018-03-07 00:45:47 7f3224bbc700 InnoDB: cannot calculate statistics for table “openmrs”.“address_hierarchy_address_to_entry_map” because the .ibd file is missing. For help, please refer to MySQL :: MySQL 5.6 Reference Manual :: 14.21 InnoDB Troubleshooting 2018-03-07 00:45:47 30893 [Note] InnoDB: Sync to disk 2018-03-07 00:45:47 30893 [Note] InnoDB: Sync to disk - done! 2018-03-07 00:45:47 30893 [Note] InnoDB: Phase I - Update all pages 2018-03-07 00:45:47 30893 [Note] InnoDB: Sync to disk 2018-03-07 00:45:47 30893 [Note] InnoDB: Sync to disk - done! 2018-03-07 00:45:47 30893 [Note] InnoDB: Phase III - Flush changes to disk 2018-03-07 00:45:47 30893 [Note] InnoDB: Phase IV - Flush complete
And then
Attempting backtrace. You can use the following information to find out where mysqld died.
2018-03-07 00:45:50 31180 [Note] InnoDB: The log sequence numbers 691816295 and 691816295 in ibdata files do not match the log sequence number 692239718 in the ib_logfiles! 2018-03-07 00:45:50 31180 [Note] InnoDB: Database was not shutdown normally!
Please note that the system which I am trying to backup is running Bahmni perfectly fine but I cannot restore the database on another machine.
We don’t know if the problem is related to the backup or the restore as every time we backed up the restore failed but the system from which we backed up is running fine.
Restore failed on “Import table space for newly restored data files” step. After that mysql died and won’t start. So we had to use innodb_force_recovery = 4 (why 4 is still unanswered as we tried 1,5,6 too!) in file /etc/my.cnf. But this at least started mysql.
The /var/log/backrest/mysql_backrest.log file has only this information:
20180307-00:39:26 STARTED : Restore using xtrabackup /data/openmrs//20180307003023_full
20180307-00:45:30 STARTED : Restore using xtrabackup /data/openmrs//20180307003023_full
The /var/log/mysqld.log file has series of these statements for almost all the tables:
2018-03-07 00:45:46 30893 [Note] InnoDB: DISCARD flag set for table ‘“openmrs”.“DATABASECHANGELOG”’, ignored.
Followed by series of these statements for almost all tables:
2018-03-07 00:45:47 30893 [Warning] InnoDB: Table ‘“openmrs”.“address_hierarchy_address_to_entry_map”’ tablespace is set as discarded.
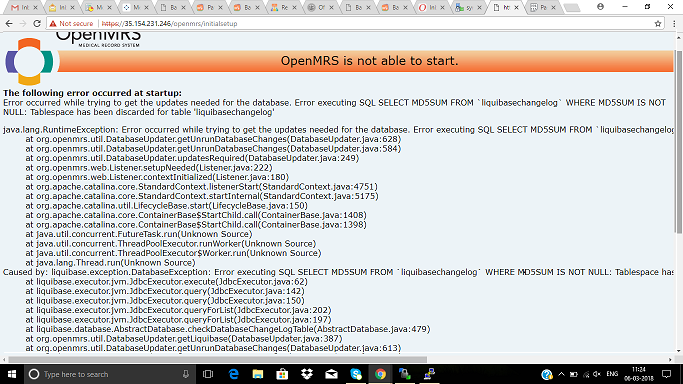
The openmrs log shows as follows:
Caused by: liquibase.exception.MigrationFailedException: Migration failed for change set liquibase.xml::add_creator_for_reporting_report_design::mgoodrich:
When tried select statement on reporting_report_design table it showed the error “tablespace has been discarded”. The select statement failed on this error for almost all tables.
So from the command prompt we ran /opt/bahmni-installer/bahmni-playbooks/roles/mysql-db-restore-incr/files/restore_tablespace.sh (as the restored had failed files were still in /tmp/restore_dir) with 4 parameters as mysql user id, password, openmrs, IMPORT. This recovered the tablespace for all tables.
Then restarting mysql without innodb_force_recovery = 4 in /etc/my.cnf helped to bring up OpenMRS and Bahmni.
(Sorry, I’m going to have to admit that this is way outside of the scope that I know anything about.)
I wonder if there is something about your database that is unusual which means that the standard database dump command is leaving a badly-formed database. Can you think of anything you’re doing here that’s outside of the usual for Bahmni implementations?
I am learning too!
Though the source machine which we are backing up has been upgraded from Bahmni 0.89 to 0.90 the rest is vanilla implementation so nothing unusual. We are restoring the backed up data on a target machine (fresh Bahmni 0.90 installation) to ensure that backup is successful.
Since we had to recover the target machine as explained above due to discarded tablespace we did (and plan to do) the following:
Backed up another machine having Bahmni 0.90 and tried to restore that data on this target. But again the restore fails on the same step “Import table space for newly restored data files”. This may mean that our target machine itself has some database issues but that needs to be tested further.
(Actually we should have done this first but it’s pending) Restore the source backup on a different target machine with freshly built Bahmni 0.90 .
Hi @ramashish,
We had this issue with database dump on 0.89v Bahmni which was fixed as part of 0.90v Bahmni. (We came to know about this issue as part of 0.90 release testing). So you will not face database restore issue with 0.90v Bahmni database.
Let me state again that the source machine WAS 0.89 and we upgraded to 0.90 and still faced this problem. We are still investigating whether it is the source or the target machine that’s causing the problem.
@ramashish Even if you have upgraded from 0.89 to 0.90, you will have the database that has come with bahmni 0.89 installation. There won’t be any change in the database with upgrade. To solve this issue either you have to restore 0.90v database from this repo OR fix the existing dump that has come with 0.89. Let me know if you need any help.
Though we will try the solution that you have suggested but would like to bring this up to your notice