Thank you @bashir for taking the time to go through this post and raising important design considerations ![]() I’m glad you are interested in this conversation of having a community-driven ETL pipeline.
I’m glad you are interested in this conversation of having a community-driven ETL pipeline.
Yes, there are two components to it: OpenMRS CDC - docker containers and Batch/Streaming Codebase This is prototyped using python; however, once the community is on board with the idea of designing and developing a new community-driven ETL/ELT pipeline, we can use whichever programming language that favors the majority. Also, the design of the ultimate pipeline should be driven by the community, and it doesn’t need to use this architecture; this is just but a proof of concept. Please let me know if you need help running the CDC and bringing up the pipeline.
The first component i.e., CDC component, supports all versions of OpenMRS; however, we haven’t tested the second component on version <2.X. Ultimately, we need a pipeline that is version-able and can support any version of OpenMRS. Therefore, moving forward, we should come up with a design that evolves with OpenMRS versions. The good thing is that OpenMRS base table schema rarely changes.
This is an excellent suggestion, during the design session of the ultimate pipeline, we should definitely consider Beam. We did not explore other options because spark provides a unified API for both streaming and batch mode. Essentially you can write one pipeline for both modes using spark. However, a pure unified streaming/batch pipeline puts a very strong assumption on the ingestion mechanism of the pipeline, i.e., it assumes your streaming/batch input shares identical source, schema, and structure. This is almost impossible to pull without modifying OpenMRS API to support streaming or alternatively pre-structuring the input data stream/batch. Lambda architecture comes to the rescue when you do not have the luxury of modifying pre-existing system. Lastly, another important attribute that we need to consider while selecting the ultimate tech-stack is: guarantee for “exactly-once” processing semantics (with respect to availability and consistency). In essence, we don’t want to miss some updates in case of a disconnection between the data source (OpenMRS) and the ETL/ELT pipeline.
Delta Lake supports columnar file format and is actually built on top of Parquet files, with support for both batch/streaming including, ACID transaction and schema evolution e.t.c. When we finally design the ultimate pipeline, I think it will be important to allow flexibility for selecting the intermediate storage of choice - whether on-premise or cloud storage. Ultimately we should make it configurable.
Delta, through spark API, supports SQL like queries. Both PySpark batch/streaming context provides out of the box support for SQL-like queries. I can’t stress enough that we need the flexibility of selecting the intermediate storage of choice. The community won’t be receptive if the ultimate pipeline doesn’t support this flexibility. As a strawman’s starting point, we should have a default intermediate storage while allowing support for popular storage systems.
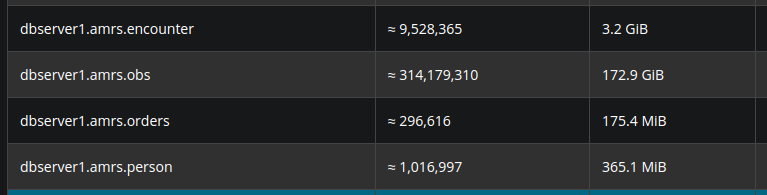
The entire pipeline has been tested on a server with 8-cores and 30GB of RAM; however, only 21 GB was available since other containers were running on the same server.
Again thank you for following up with these design questions, please let me know if you need further elaboration.