A major focus within the OpenMRS community is how to efficiently extract data from the production database for reporting, analysis, and clinical decision support. Using modern data engineering tools to extract and transform data from OpenMRS can greatly reduce workload from the production line as well as improve the workflow of reporting and analysis. Additionally, the manual process of designing and developing ETL queries have been proven to be time-consuming, tedious, complex, and not scalable. To encourage collaboration within the community, a modern approach is desperately needed. AMPATH and Antara have been collaborating the past few months in designing and developing a modern ELT pipeline (proof of concept) using widely used data engineering tools and programming language. Here is what we have accomplished so far
-
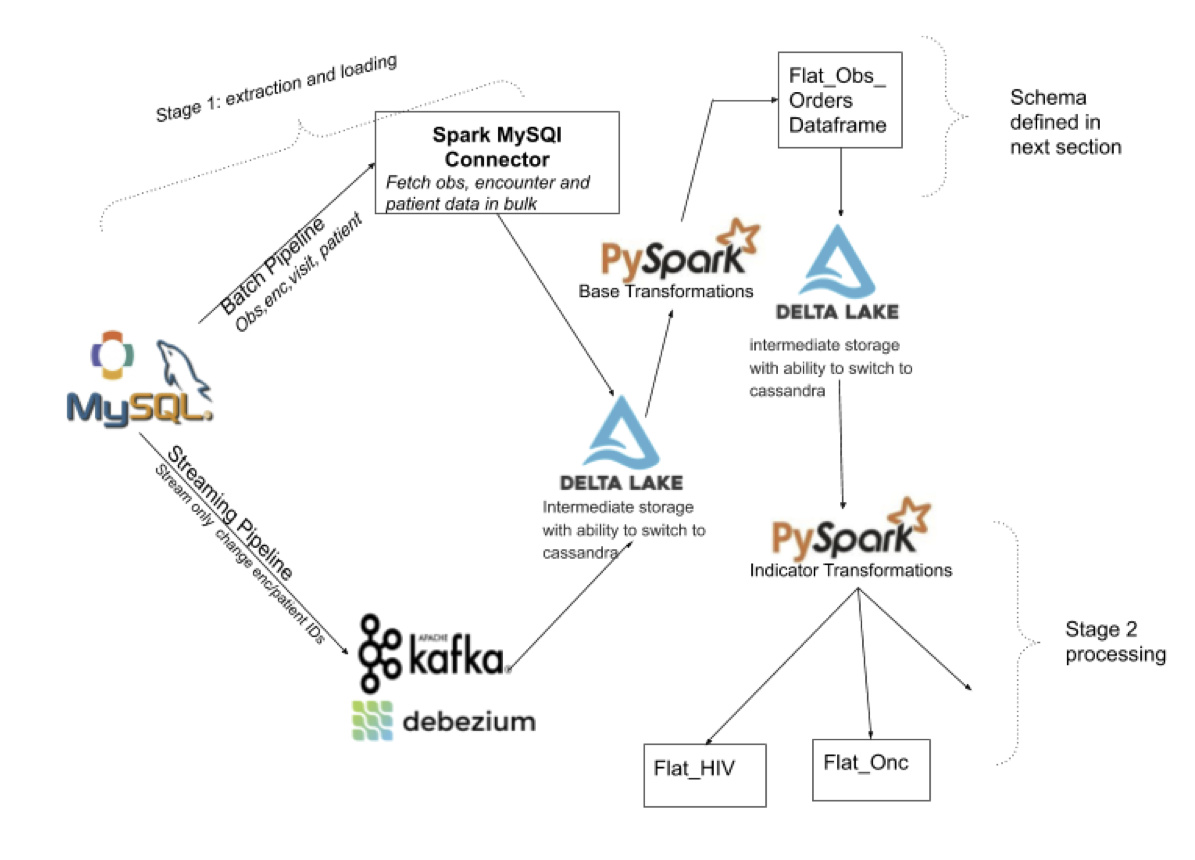
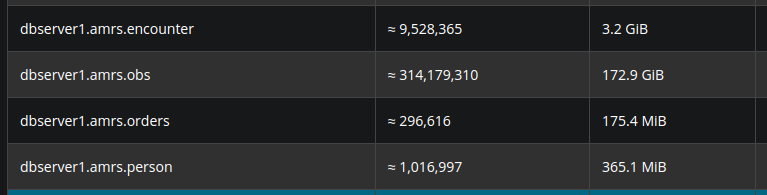
We have been able to design a friendly-to-analytics DataFrame/Table schema for OpenMRS data that is relevant to many different groups and not specific to any OpenMRS implementation. As a strawman starting point, the derived dataframe consist of data elements extracted from Obs, Encounter, Orders, and Person table, with the flexibility to include other desired data elements.
-
Instead of using the ETL paradigm, which discourages collaboration effort, we leveraged on ELT pattern to extract and load data out of OpenMRS. Additionally, using ELT provides the ability to store extracted data on an intermediate datastore, so that the data can be efficiently loaded into an analytics environment/platform of choice. Currently, the intermediate datastore supports delta lake and Cassandra with the ability to plug in NoSQL/RDMS of choice. All logic for sourcing, sinking, and transformation is implemented using opensource stacks such as spark, debezium, kafka, casssandra, and recently open-sourced delta lake.
-
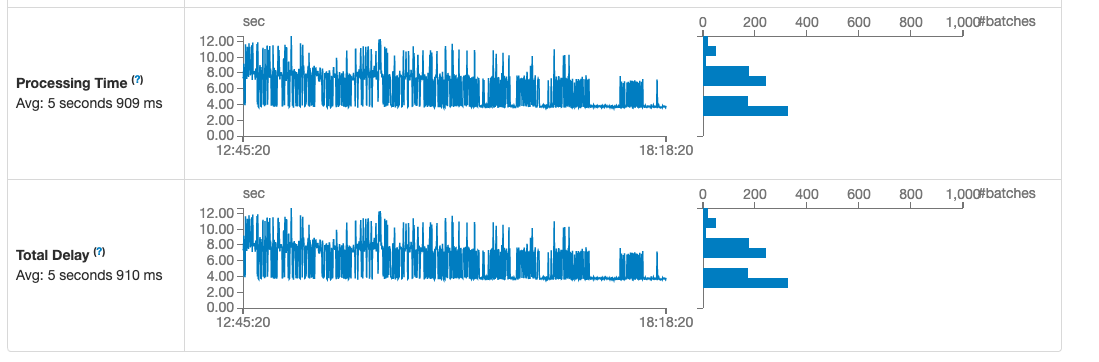
The pipeline supports both batch and streaming modes. After the batch process is completed, all updates done through OpenMRS are incrementally updated to the intermediate data store. To avoid code duplication, the batch pipeline and streaming share some common algorithms, with the ability to extend it very easily. We have tested this pipeline on a production level during peak-hour of data-entry (~80 events per second) with minimal latency (~ 4 seconds)
For more details, we will have a brief demo during Burke’s ETL vision statement meeting (yet to be scheduled), feel free to join us, and we will be able to discuss possible directions we can take as a community. Hopefully, the call and the proof of concept will take this conversation to the next level. Please feel free to post follow up questions or some of the things you need or would like to see /discuss during the demo. Should you need immediate clarification, please feel free to post via this thread.