Hi All
We at Mekom have been asked to build a Data Dashboard for the ICRC project. While doing so we would like to know if there is any interest in such a feature from the broader community. As usual, having involvement from other teams helps the feature live a better life and also potentially influences architecture decisions in order to support (or at least future-proof against) broader use cases. So, please let us know if this topic is interesting to you.
Here is a brief overview of the feature as I currently understand it from @delphinep and team.
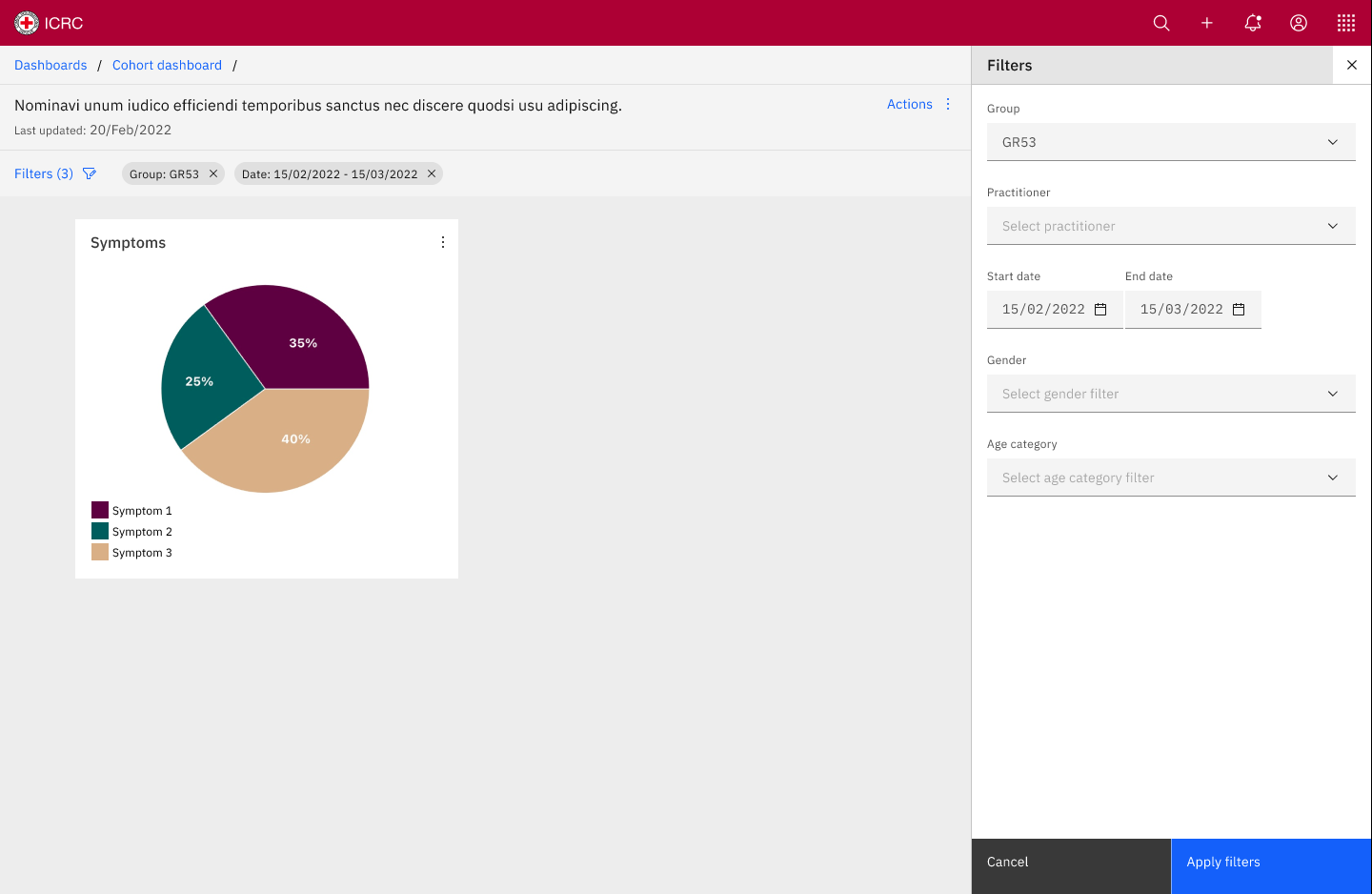
Let’s start by saying that a Data Dashboard is made up of Chart Widgets
Chart widgets contain things like the following:
- Pie charts: “age groups of patients”, “gender of patients”, “locations of patients”, “types of violence” , “types of vulnerability”, “types of symptoms”, “percentage of perpetrators that are weapon-bearers”
- Lists: “patients who have missed last 1,2,3 months of group sessions”
- Numbers: Counting patients with “sleeping problems”, “suicidal ideation”, “victims of rape that have not recieved medical attention”
- Bar charts: “missing data by form type”
- Histograms: “pre/post-scores of a program”, “days between event and data entry”
- Misc: Difference between Pre-scores and Post-scores to see effectiveness of a program
Combining widgets then makes up a dashboard. A program coordinator can create program-wide standard dashboards. Each user can modify a dashboard to add or remove above “widgets”. They can rearrange widgets on the page. Dashboards can be saved, copied, and shared.
There is also a need to have all widgets be globally affected by filters. I.e. all widgets will simultaneously filter down on parameters: practitioner (session and admission), structure, group, location, country, region, program, date range (session and admission), gender, age range, referral from, referral to, type of violence, weapon-bearing perpetrators).
Once this point is reached though no further drilling is allowed - Specifically it is not expected at this time to go from this dashboard into a patient’s chart.
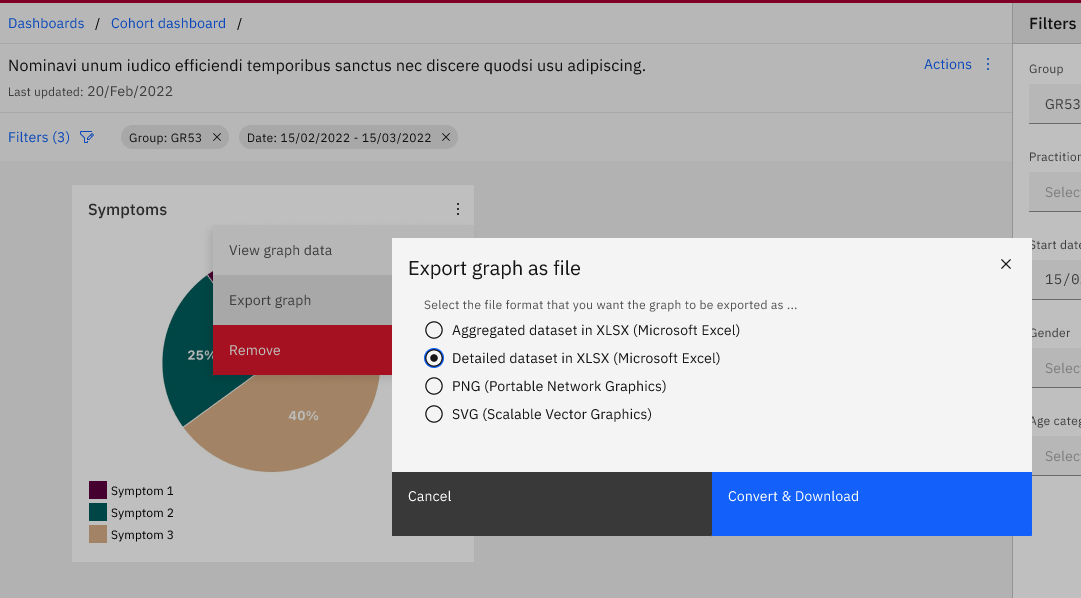
To get past this it is allowed that some user can “download data” so that they can do further drilling if they want. What all this data download includes is not very clear, but it would potentially have patient identifiers, but not names or addresses.
Currently there is an interest to build this product in OpenMRS using Carbon chart components (roll it ourselves). There has been many and intense discussions about instead using either existing licensed or open source BI tools. There is some hope from the team that this is simple and straightforward work and we will not need to interface with another product, but anyway we are making work estimates for both. The team wants that the scale of the product will be contained with minimal scope creep. The current list of user stories is here.
Please leave comments below. @delphinep will be responding to questions on this thread.
Thank you