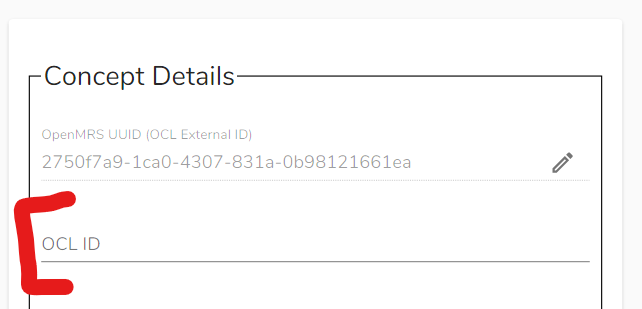
We keep hearing that OCL for OpenMRS users are confused by what to put in the “OCL ID” field, and how to structure their ID here:
I have 2 thoughts:
How are folks at PIH, MSF, and other sites structuring this ID? Any guidance/advice you’d like to share with other orgs? (@ball@michaelbontyes@akanter@burke)
It would be great to add some helper text here to guide future users directly in the product. So we will take your feedback/advice from this thread and create helper text; using Material Design it would sit below the field like this:
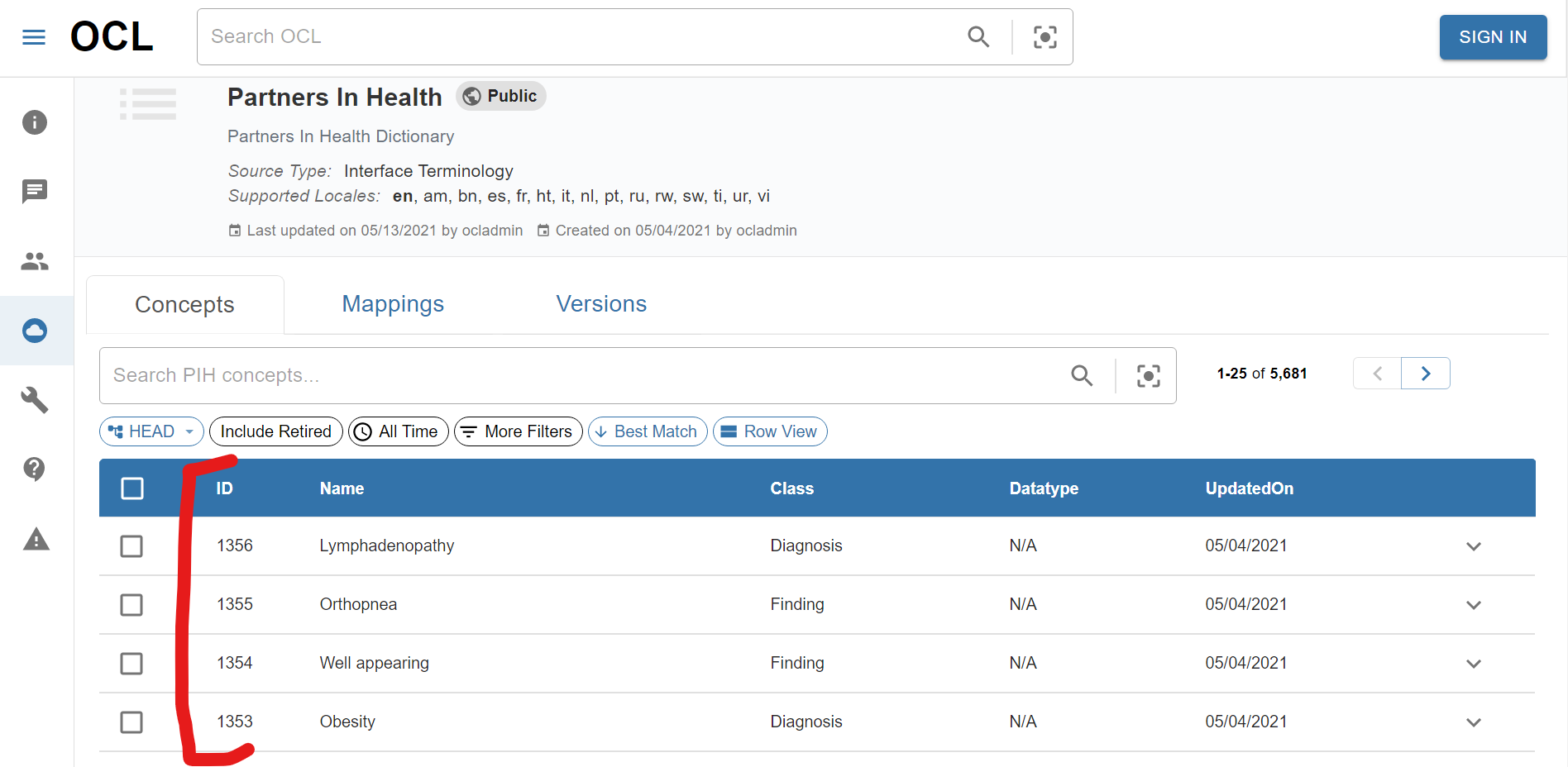
From an OpenMRS perspective, this field is only used in concept mappings. For example, CIEL has a concept with an OCL ID of 1066. When I create a mapping from a custom concept to CIEL, that would be the ID I use to refer to the CIEL concept (i.e., it’s the ID that’s populated in the Concept field in the Mappings / Set Members / Answers table. In an OpenMRS concept dictionary, this OCL ID will show up, so that my mapping in OCL that says that my custom concept is the same as CIEL:1066 will also appear in my OpenMRS dictionary as being mapped as the same as CIEL:1066. That’s really the only place it seems to be used. For OpenMRS dictionaries imported into OCL (CIEL and PIH), this field is being populated with the concept_id. For custom sources, it can really be whatever you want.
From an OCL perspective, the ID is a unique 255 character string that identifies the concept in the source. So OCL will support CIEL:1066 and PIH:1066, but not two concepts in the CIEL source with the ID of 1066.
As for helper text… well, it’s the ID you want to refer to this concept as, so maybe something like “Identifier for this concept in this source” (I’m having a hard time turning that first paragraph into anything really comprehensible).
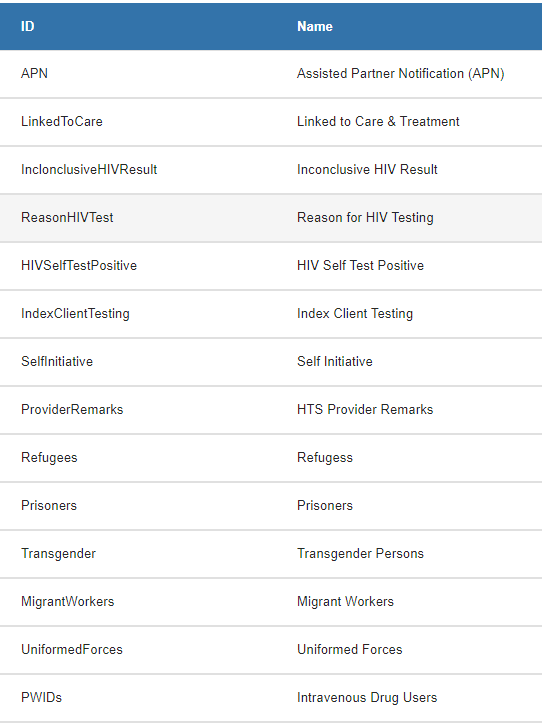
It looks like it works the opposite direction as well - e.g. below you can see how the custom OCL IDs created via OCL for OpenMRS became the ID in OCL.
I think this points to us needing a convention for how to write this ID.
My point was that it’s just the ID in OCL. If you imported those concepts into an OpenMRS instance, they would end up with a numeric concept id. I.e., when, in OCL for OpenMRS we called the field “OCL ID” it really just is the OCL ID.
To me, this sort of convention feels like overkill. After all, presumably that’s meant to refer to concept 01 in the MW source belonging to PIH… All of that metadata is already part of the OCL structure.
That said, maybe @akanter has some ideas on a best practice to structure custom code identifiers?
That was just the way that the CIEL concept ID could be persisted in OCL. Those concept ID’s are simply sequence numbers. There is no special meaning to the ID. As a matter of fact, it is generally better that IDs do not have intrinsic meaning. Some involve a check-digit, but to be honest, if there is no specific meaning to the sequence of numbers, I don’t know what a checkdigit provides. In some situations, there are namespace identifiers or prefixes that appear at the start of a sequence number, and there it would make sense to have a check digit to ensure that there hasn’t been any mixing up of the numbers.
Early versions of ICD (e.g., ICD-9) made this mistake, trying to create a hierarchy in the ICD-9 codes and then ran out of space in the hierarchy and ended up re-using identifiers (shudder).
A checkdigit is a means to provide built-in validation for identifiers when they are manually entered or transcribed. If an identifier is never handled by humans, the checkdigit isn’t necessary. But when humans touch things, they make mistakes. A checkdigit can prevent 90% or more of simple transcription errors. That’s why they are used for credit card numbers.
On the checkdigit, I think that would apply when there are specific combinations of characters that are acceptable. If there are sequential numbers then there would be no reason to have a check digit since all combinations of characters would theoretically allowed.
FYI – A checkdigit adds internal validity regardless of what characters are used in the code. Said another way, calculating a checkdigit from the rest of the code helps reduce the chance of a code being mistyped (since, in most cases, a change in the code would change the corresponding checkdigit). When a human is typing in codes where all combinations of characters are allowed (e.g., sequential numbers), it’s a perfect use case for adding a checkdigit to reduce that chance of a user accidentally mistyping a single digit. For example, LOINC uses sequential numbers for their identifiers and adds a checkdigit to reduce transcription errors.