This is great information @mogoodrich. I’m sure @jdick and others with large databases would appreciate sharing best practices for handling big database changesets.
We should probably update or Database Update Conventions to include the point about changes to obs. In general, any changes to potentially large core files like obs should be vetted for alternative approaches and, when deemed necessary, coordinated in order to minimize the times we touch those tables.
Are there any plans to partition Obs table vertically. I mean, if value_coded, value_numeric, … can be stored in separate tables, that would really ease up the burden on Obs table.
@ssmusoke writing queries will be a bit complicated, but the end user won’t have to wait for endless hours to pull reports, especially the ones using grouping.
I’ll see if I can cook some numbers to support this. First of all, is the distribution between coded/numeric/text even considerably even to entertain the idea.
Oh yes joining to the obs table today is already very difficult, breaking it down further adds up to 4 additional joins per loop through the obs table.
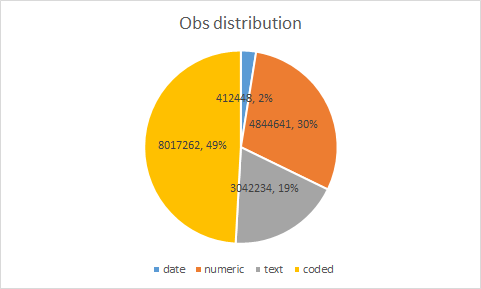
@ssmusoke I performed a primitive test on our largest implementation. First the distribution of obs table (16M rows) by data type (I’m skipping complex and drug, being negligible):
Here’s a query, which gives a count of patients on TB treatment, having a positive GeneXpert test, but don’t have a CAD4TB Chest X-Ray score above 50. No real use, but just a query using both coded and numeric obs.
select e.encounter_id, e.encounter_datetime, e.location_id as treatment_site, count(*) as total from encounter as e
inner join encounter as gxp on gxp.patient_id = e.patient_id and gxp.encounter_type = 172
inner join obs as gxp_result on gxp_result.encounter_id = gxp.encounter_id and gxp_result.concept_id = 162202
where e.encounter_type = 29
and gxp_result.value_coded = 1301
and not exists (
select * from encounter as e2
inner join obs as o on o.encounter_id = e2.encounter_id
where e2.patient_id = e.patient_id and e2.encounter_type = 186 and o.value_numeric > 50)
group by e.encounter_id, e.encounter_datetime, e.location_id;
create table obs_datetime like obs;
insert into obs_datetime select * from obs where value_datetime is not null;
create table obs_numeric like obs;
insert into obs_numeric select * from obs where value_numeric is not null;
create table obs_text like obs;
insert into obs_text select * from obs where value_text is not null;
create table obs_coded like obs;
insert into obs_coded select * from obs where value_coded is not null;
reset query cache;
select e.encounter_id, e.encounter_datetime, e.location_id as treatment_site, count(*) as total from encounter as e
inner join encounter as gxp on gxp.patient_id = e.patient_id and gxp.encounter_type = 172
inner join obs_coded as gxp_result on gxp_result.encounter_id = gxp.encounter_id and gxp_result.concept_id = 162202
where e.encounter_type = 29
and gxp_result.value_coded = 1301
and not exists (
select * from encounter as e2
inner join obs_numeric as o on o.encounter_id = e2.encounter_id
where e2.patient_id = e.patient_id and e2.encounter_type = 186 and o.value_numeric > 50)
group by e.encounter_id, e.encounter_datetime, e.location_id;
First query took 1.781 sec vs the other one after partitioning) which took 1.046 (not including fetch time).
The tables were created as copies, so all indices and keys were copied as is.
Is it possible to collect more data on this from several implementations, especially using DBMS other than MySQL?