I am interested in the Extend Performance Tests project on this year’s Google Summer of Code project list.
I went through the project description and got some understanding on “What is perfomance testing?”, how Gatling works through it’s documentation, what are the challenges on this and what is the current situation using openmrs-contrib-performance-test while familiarizing my self with this.
Currently i’m working with switching Hibernate Mappings to JPA Annotations while getting more familiar with openmrs-core .
I would love to get guidance and advices to understand this project more deeply.
Looking forward for your thoughts and can’t wait to learn from your experiences.
@jayasanka I’m currently on identifying new personas for our performance testing scenarios. So far, we have doctors and clerks implemented, but I’m unsure how to determine additional key personas in OpenMRS.
Could you share some guidance on how to approach this please?
Once I identify the personas. i believe the next step would be to think about more real world scenarios for them. Am I correct? please correct me if my understanding is wrong.
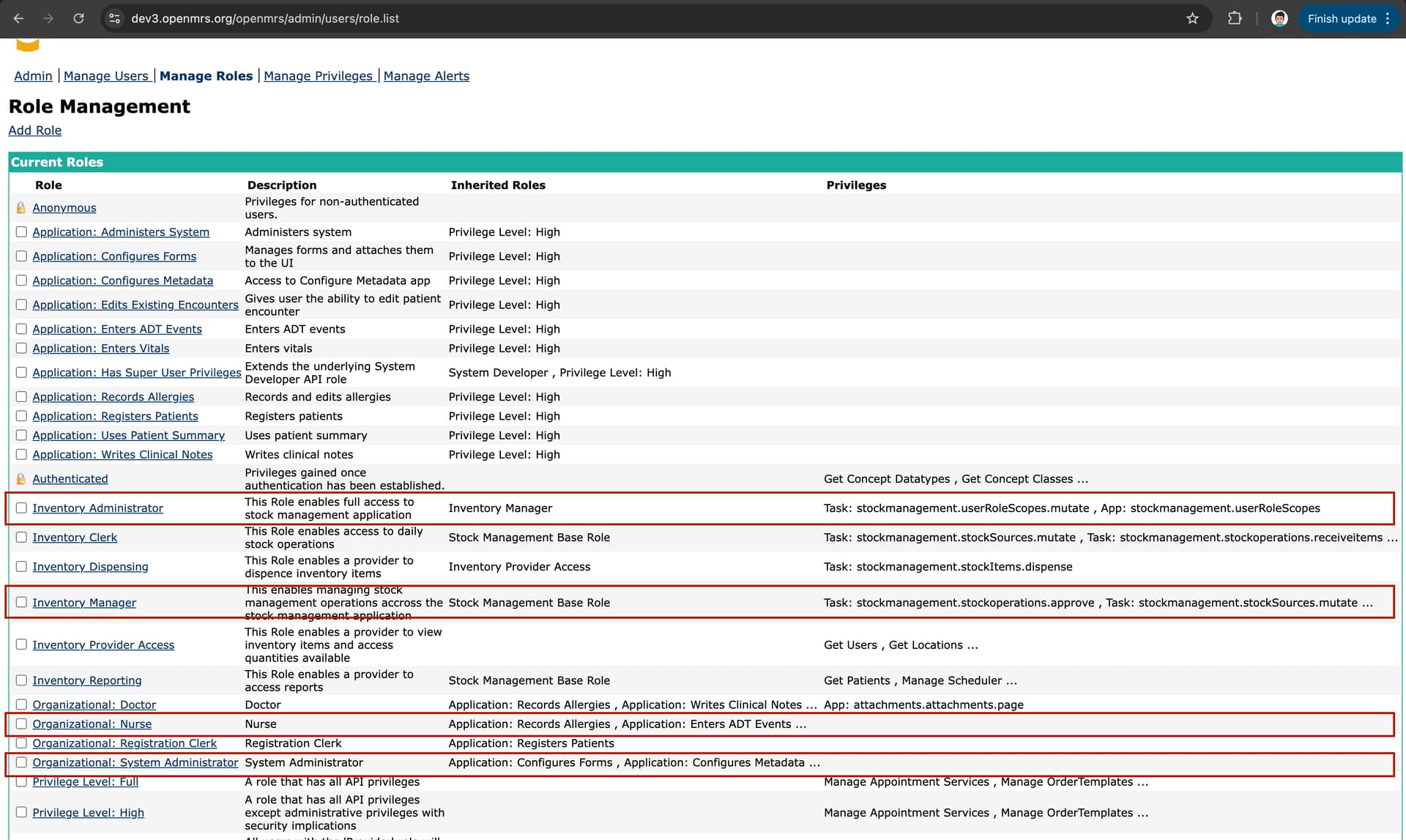
I found these user roles and picked some main roles as by reading the description of them. Do these roles seem like the right choices, or should I consider any other roles as more important?
When choosing a persona, you need to consider whether performance testing is actually necessary and what tasks they perform in the real world. Based on that, you can select the right persona. A nurse is a good choice, but it’s important to consider the real-world tasks that other roles have as well.
I would love to learn why this is happening, as my local project is up to date, and the Docker container is running perfectly.
@jayasanka@bawanthathilan
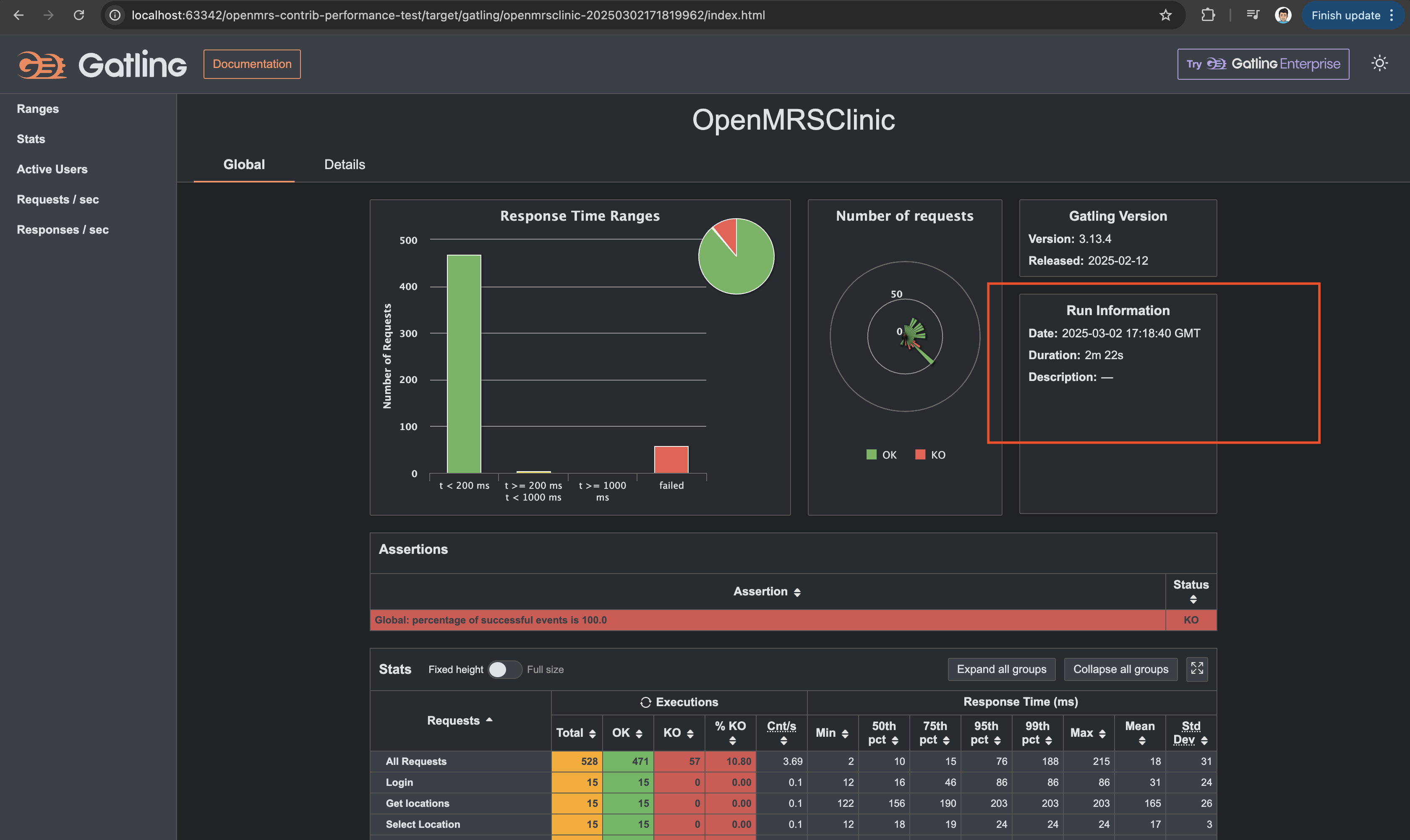
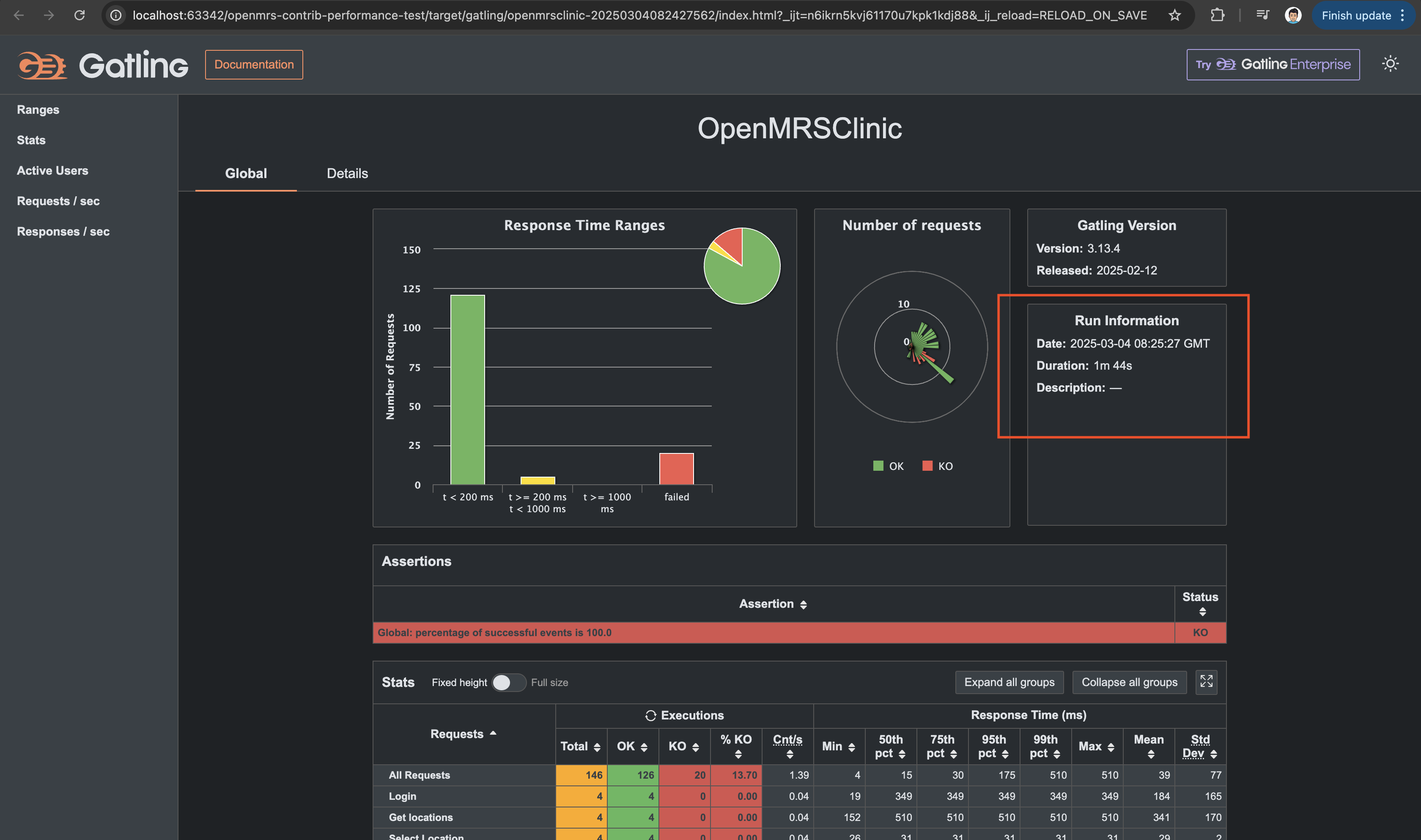
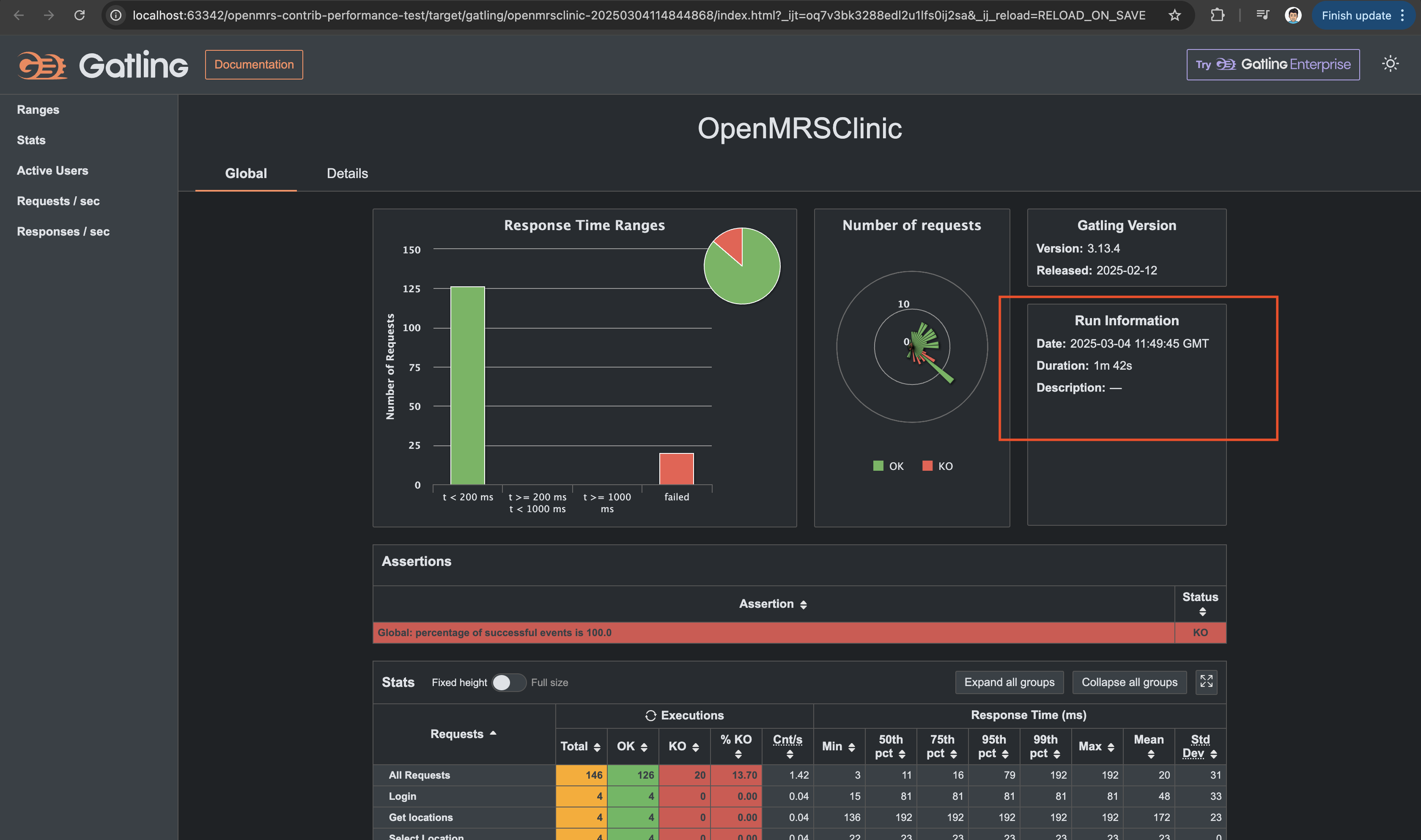
Currently, Gatling is using its default standard benchmarks. However, based on my understanding, benchmarks should be determined by analyzing all endpoints, identifying the critical ones, and then defining expected response times accordingly.
The error rate metric is currently at 0% (100% success) since we don’t anticipate failures in our current scenarios. From what I understand, error rates typically become relevant when testing peak loads, where failures start occurring as the system reaches its limits.
As for CPU load and memory usage, Gatling doesn’t track these metrics directly. We’d need additional tools like Prometheus or cloud-native monitoring solutions such as CloudWatch for a more comprehensive performance analysis.