1. Perform patient match taking considerations of the previous run (incremental patient matching).
This method will avoid unnecessary record comparisons.
A match will be performed upon,
addition of new patients or
changes in patients’ records
After an incremental match a separate output will be created.
This incremental matching is specific to a strategy.
An output from previous run can be selected as the memory for the next run(eg. For strategy “A” there are 50 runs in last 3 months, so it should be possible to pick one output from the 50 as the memory for the next match)
2. Avoid repeated manual reviews of previous manually reviewed matches
Hi @burke with the help of the brainstorm session with you, Dr. Shaun, and Andrew I have finalized this project plan and some important points of the discussion are included in here Coding Period May 30, 2017 - August 21, 2017
Working Period May 30, 2017 - June 26, 2017
Phase 1 Evaluation June 26, 2017 - June 30, 2017
Working Period July 1, 2017 - July 24, 2017
Phase 2 Evaluation July 25, 2017 - July 28, 2017
Problem with the current version is when a patient match is done the module does not consider the output from prior run to compute the new output. Main goal is to refactor this module to perform incremental match instead of isolated matching processes.
1. A method to perform patient match taking considerations of the previous run (incremental patient matching) [May 30, 2017 - June 26, 2017]
A match will be performed upon,
addition of new patients or
changes in patients’ records
The basic idea of doing this is to find what are the records that match with the above two criteria and perform a match with those records with every other record
A query to get what had changed/added in the list of patients’ records.( A method Dr. Shaun suggested was to keep a running list of as to what are the potential pairs that don’t match )
After an incremental match a separate output will be created.
This incremental matching should be specific to a strategy.
It should be possible to select between a particular strategy we are going to select as the memory for next patient match (for eg. For strategy “A” there are 50 runs in last 3 months, so it should be possible to pick one output from the 50 as the memory for the next match)
2. Module should be able to perform patient match with each and every record with it self despite of the output from prior runs (In simple terms not an incremental patient matching) [July 1, 2017 - July 12, 2017]
The reason for this because there might be issues with the previous run
3. UI changes to reflect these functionalities [July 13, 2017 - July 20, 2017]
There are a some milestones you could call out here:
Come up with query to detect new/changed patients. I think this will have to be generic. In a really fancy version, we would detect only changes in attributes used by the strategy, but I think that level of fanciness is out of scope for now.
Refactor module so, by default, it just runs matching on patients who are new/changed since strategy last run.
Validating our approach (using small set of demo patients)
This is be a relatively small change (i.e., just exposing an option to ignore date of last run), so hopefully won’t take too long to implement.
In test-driven development (what we should be striving for), tests should be written before code.
Hopefully we’ll be getting in some code review along the way.
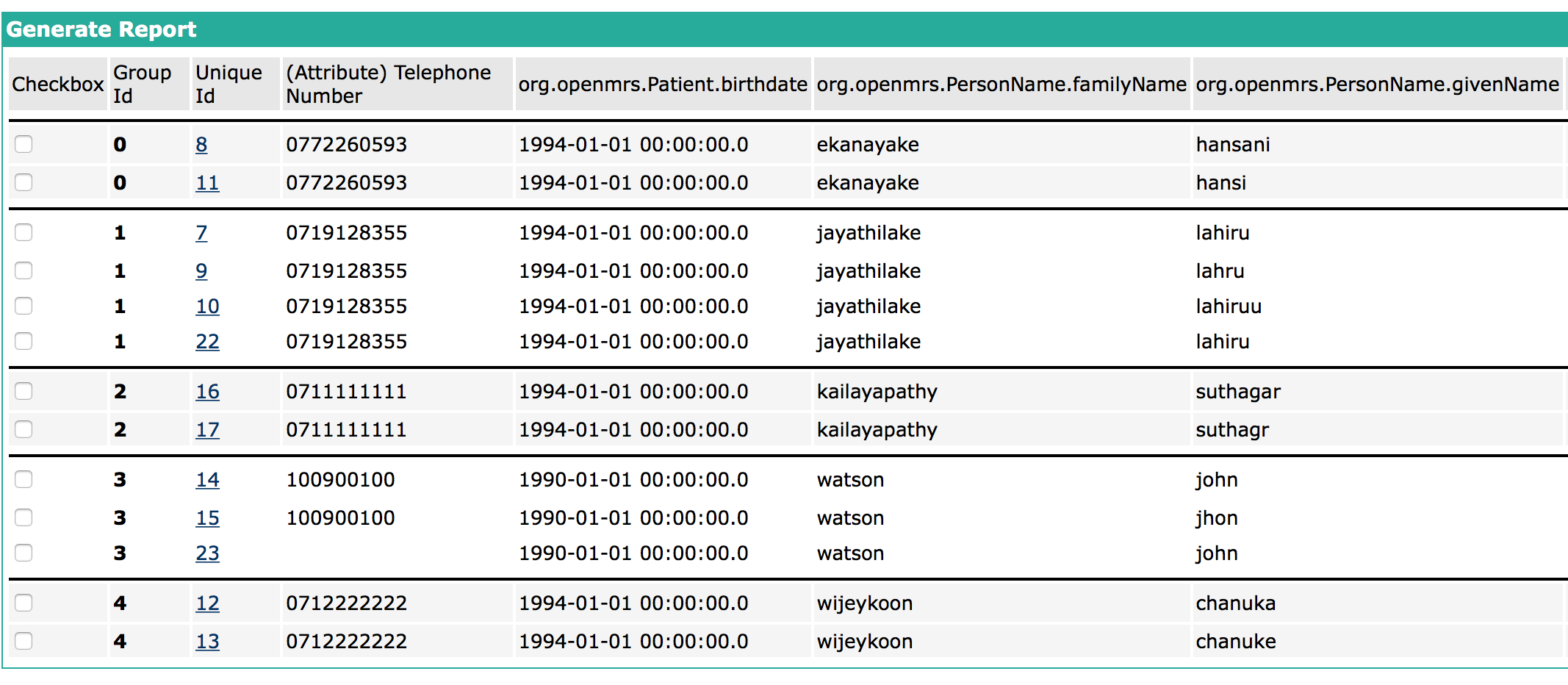
I have a confusion regarding the patient matching process. If I do a match with a certain strategy “A”, I will get possible duplicates to be merged as in the following image.
If I rerun the match with the same strategy In the current version of Patient Matching module I will get the same result set unless I have not performed any merge operations.
The confusion is, in the incremental matching process, given that we ignore the merge operations and carry a match with the same strategy, should the module display those possible duplicates or should it ignore those patient records as they were matched earlier, back then in couple of days? (assuming that no patient is added or updated)
According to my perspective those records should not be considered in the incremental patient matching process. Am I right?
I would expect to see any new additions alongside previous results – i.e., each iteration updates a single set of results rather than creating a separate result set. In other words, if a patient matching strategy is run daily for a month, there would be a single set of results for that strategy that may change over the month as patients are added/updated/merged, but the user would not have 30 distinct result sets to navigate.
Some “open source” logistics. I think you may already be doing these things, but just want review:
Tickets should be in the PTM project on JIRA. I have made you an admin for this project.
Try to define work in small, logical chunks (when possible, try to break features into 1- to 3-day chunks of work). These can be grouped into epics when needed.
Epics, when needed to group a set of issues into a larger set of work, should have a clear target so it’s clear when then epic has completed. “Initial support for incremental matching” could be an epic (as long as the acceptance criteria for initial incremental matching support are defined); however “Make patient matching better” or “Patient Matching Strategies” would not be a good epics, since it’s not clear when or if they would ever be complete.
You should be working on a fork of the patient matching repo. Please include a link to your fork in your initial post. For remote URLs, your fork would be origin and the “official” patient matching repo would be upstream. This will allow you to submit pull requests to upstream.
Create local branch with issue number as its name (e.g., git checkout -b PTM-1234)
Limit changes in that branch to addressing the specific issue. If you end up doing many commits along the way, consider squashing before submitting pull request.
Submit PR to upstream and add link in issue comment.
4. If there are couple of old reports related to the strategy, (? what)should be prompt to user asking which report is considered as the memory for the next run.
I’m hoping we can support incremental updates as seamlessly/intuitively as possible. If we’re going to support more than one output for a strategy, then we would be forced to make the user choose between updating one of those reports vs. creating a new one.
It might be better to separate the output from running a strategy from the current “report” – i.e., making a “report” an export of the current state of a strategy’s output while maintaining only one output per strategy. In this case, the one “output” of a strategy would be interactive (let the user confirm or reject matches) and a “report” would become a read-only artifact.
My exams are ongoing, until the end of this week. That is why in these couple of days I couldn’t give my full contribution to this project. I hope you understand
Thanks for the guidance and I have already created a ticket for one particular task PTM-82. As I mentioned in my blog post I’m currently struggling with that task, and today I asked help from the community and @dkayiwa is helping me to figure out the problem.
From blog post:
If there are couple of old reports related to the strategy, (? what)should be prompt to user asking which report is considered as the memory for the next run.
This one because as, in our chat with Dr. Shaun and Andrew I thought user will be asked to select a starting point for the next run.
Sure I will change it then accordingly.
I have already completed two main parts of the Patient Matching 2.0 project. The two tasks are,
PTM-82PTM-83 PR: https://github.com/openmrs/openmrs-module-patientmatching/pull/35
I am currently working on PTM-84. Which I believe to be the last biggest part of this project. The main target of this task is to perform patient match with two datasources.
For the incremental patient matching it is necessary to have two datasources, one is for all the patients and the other one is for the patients that are fetched considering the date changed and date created. I have to implement some methods and change the code to perform this because the current version only supports for the deduplication of records when dealing with a database.
Up to now I have completed most of the tasks that I have included in the project plan.
PTM-82 - Load patients for the incremental matching
PTM-83 - Generate and save reports in incremental patient matching process
PTM-84 - Perform patient match with two datasources
I have completed the PTM-86 and the PR can be found here.
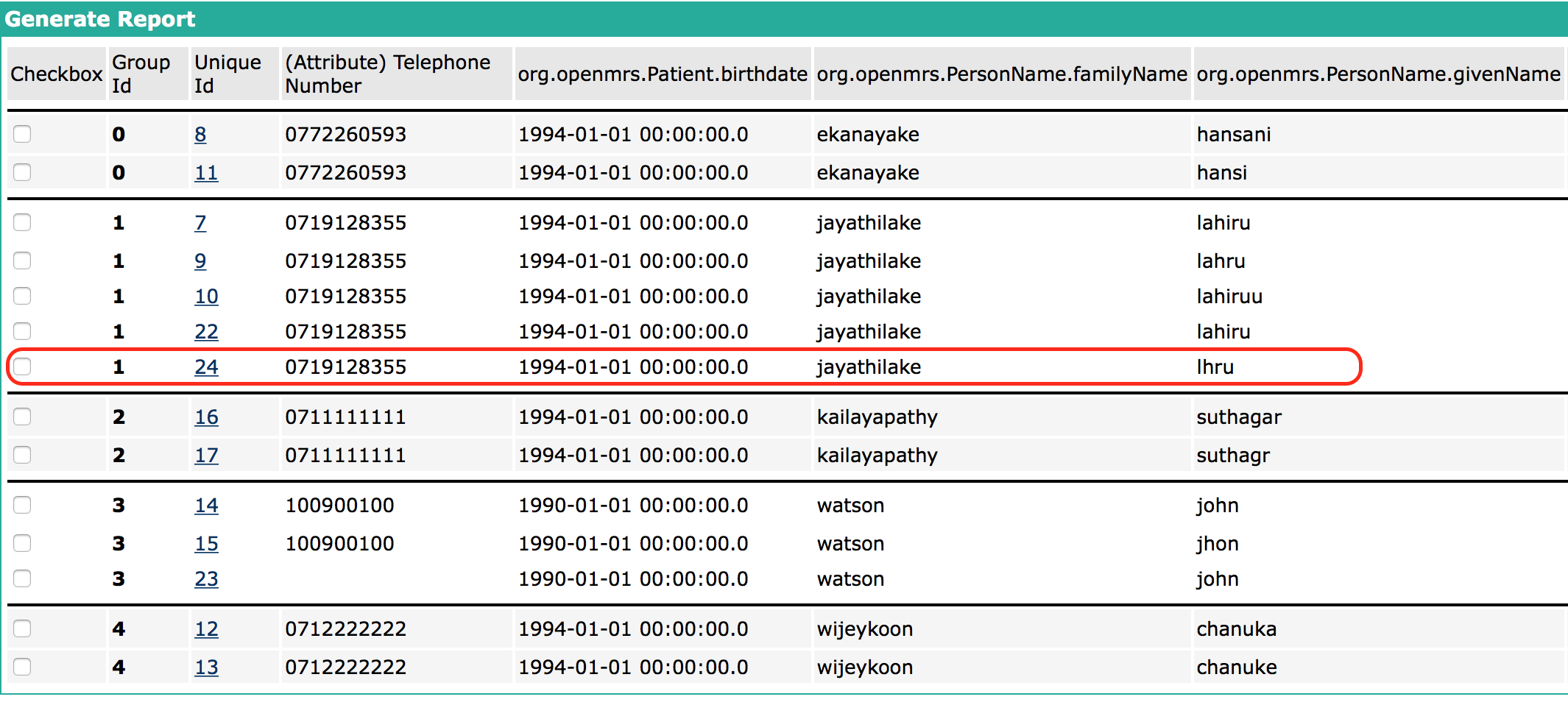
This task is to update the report whenever the patients in the report are updated in a way that those patients no longer exhibit matching properties with the rest of the patients.
For example,
Suppose there is a matched pair (say patientA and patientB). User updates the patientA in way that patientA does not exhibits matching properties with patientB.
Then the matched pair in the report will be removed.
More details about this can be found in my last week blog post.
To give a brief summary,
I was able to complete every task mentioned in my project plan three weeks before. (Mainly incremental patient matching) Since I had more time I created two issues PTM-87 and PTM-88 and completed them as well.
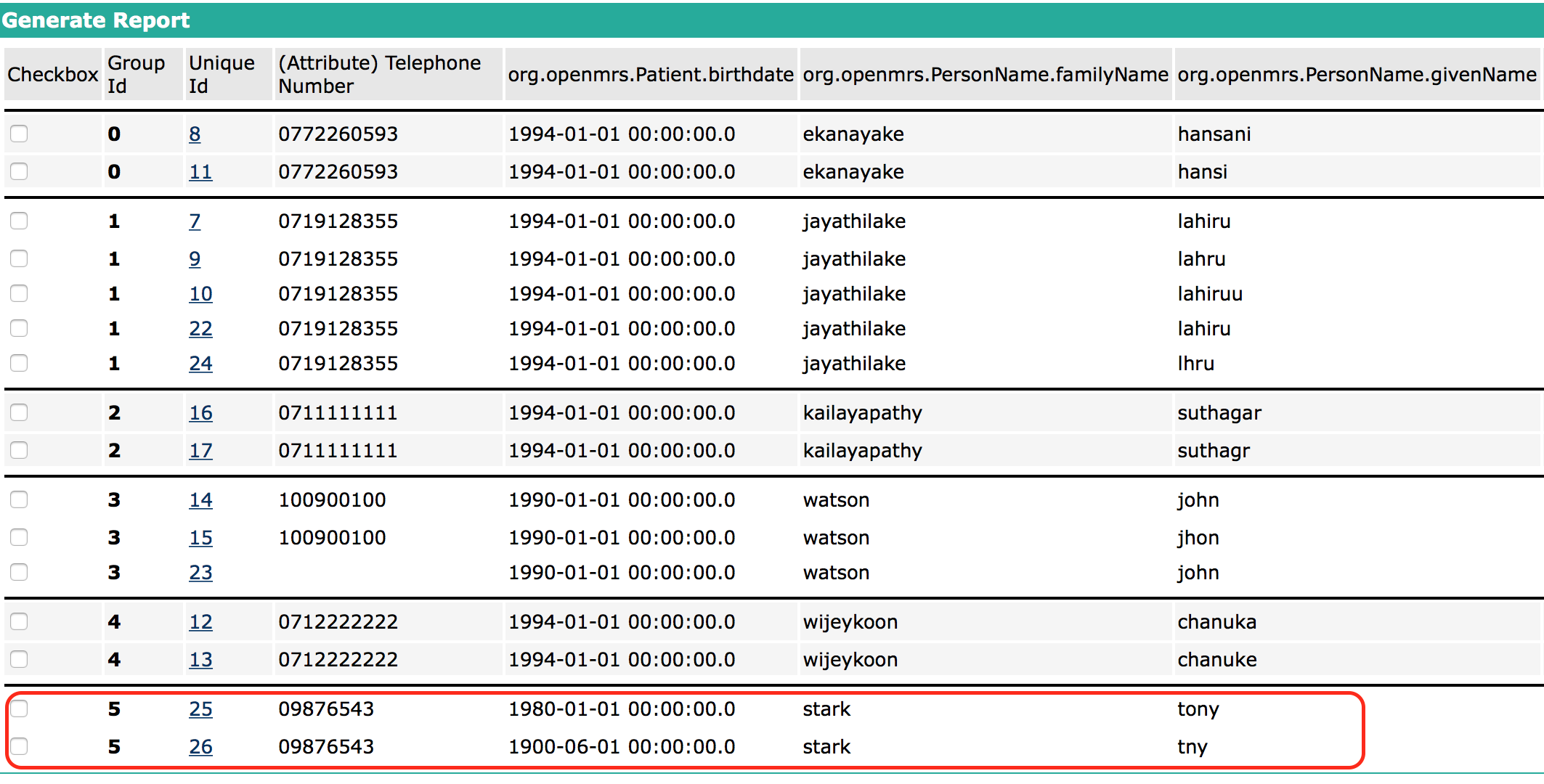
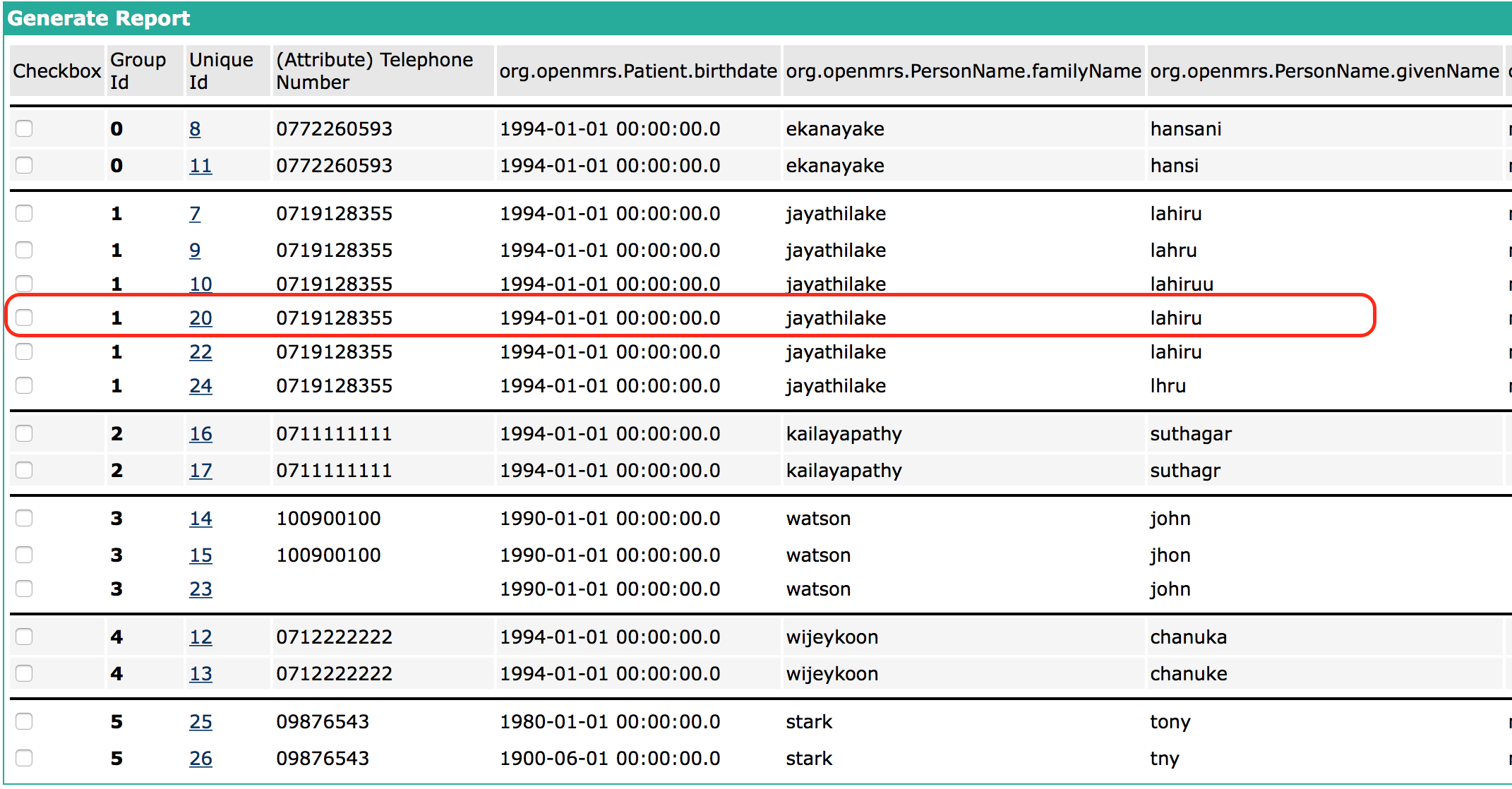
PTM-87 : to merge patients in the patient matching report
PTM-88 : to declare matching records in the report as non-matching patients. By doing this, these matches will not be considered for the next report generation process.







 ). I just created the last pull request -
). I just created the last pull request -