Hi OpenMRS Community ![]()
I’m a GSoC 2026 applicant exploring the idea of archiving voided observations. Before going further, I wanted to share a working demo and hear your thoughts.
 Watch the Demo
Watch the Demo
>> Click here to watch the demo <<
The demo covers the full flow: dry-run preview, manual archiving, scheduled jobs, analytics dashboard, and restoring archived observations.
The jobs Scheduler
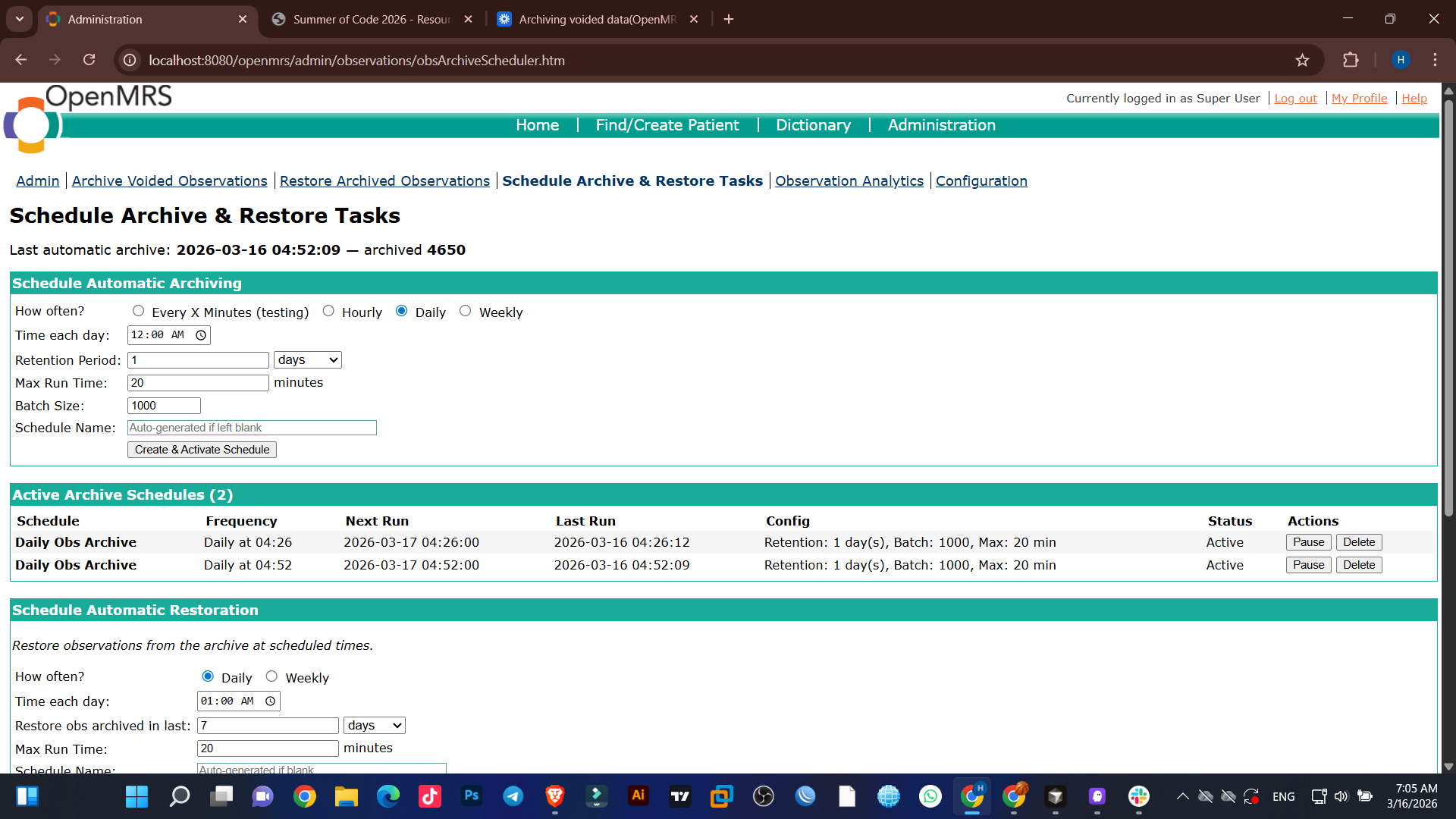
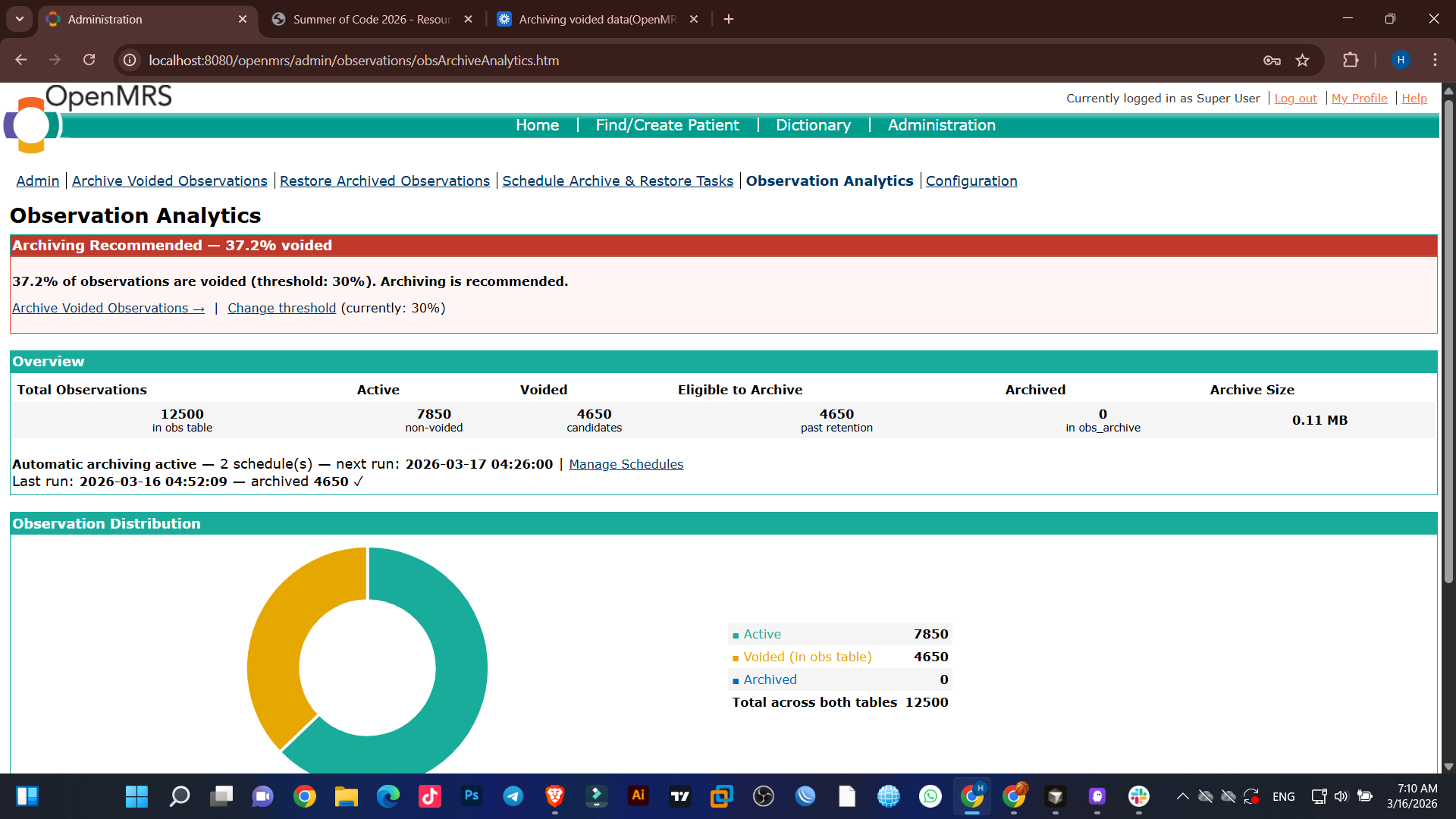
Observations Analytics
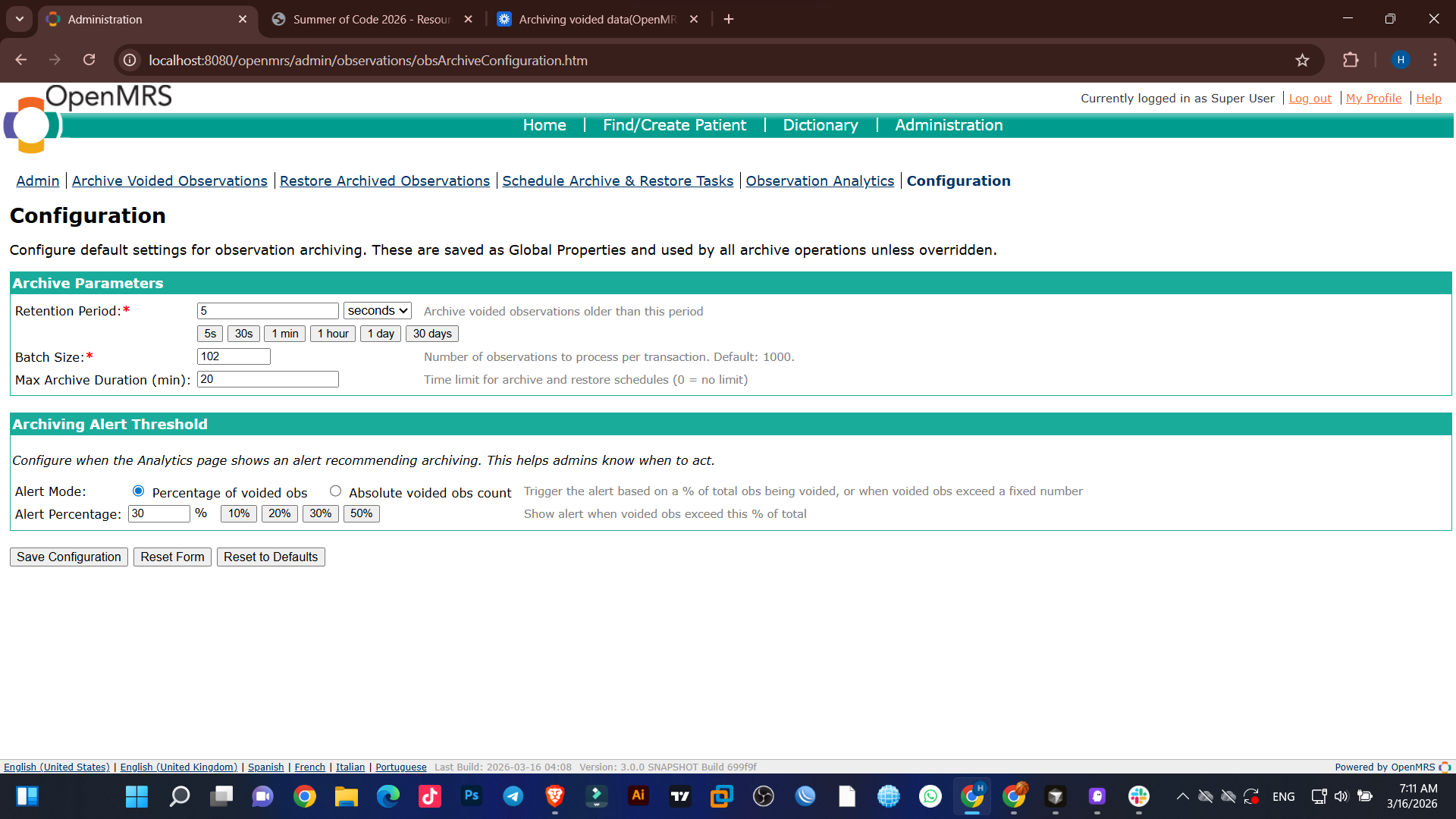
Configurations
The Problem
In large OpenMRS deployments, the obs table accumulates millions of voided rows that still get scanned on every query. This slows down patient lookups, reports, and concept searches — even though that data is clinically inactive.
Technical Strategy (High Level)
I evaluated several approaches before settling on one:
| Approach | Why I chose or passed on it |
|---|---|
| Separate archive table (chosen) | Voided obs are moved from obs to obs_archive via INSERT...SELECT + DELETE. The archive table mirrors the obs schema exactly, so every column is preserved and restoration is straightforward. The obs table immediately gets smaller — queries get faster, backups get lighter. |
| Table partitioning | MySQL requires the partition key in the primary key. Partitioning obs by voided or date_voided would mean altering the primary key of the most critical table in OpenMRS — too invasive, and partition pruning only helps queries that filter on the partition key, which most obs queries don’t. |
| JSON / schema-less archive | Serializing obs rows to JSON would lose the relational structure and make selective restores expensive (parse JSON, validate, re-insert). It also makes it harder to query the archive for analytics or auditing. Keeping the same relational schema means you can query obs_archive with the same SQL you’d use on obs. |
Soft delete flag (archived = true) |
This is essentially what voided already is. Adding another boolean doesn’t reduce table size or improve scan performance — the rows stay in obs. |
| Physical deletion (purge) | Permanently destroying clinical data is a non-starter in healthcare. Even voided observations may need to be recovered for audit, legal, or clinical reasons. |
I’d Love Your Feedback 
This is where you come in. I want to make sure this solves real problems for real deployments, not just a demo scenario.
- Implementers — How big is your
obstable? How many voided rows do you typically have? Would a 30-day default retention period work for you? - Mentors — Does this approach align with the direction you’d want for this GSoC project? Any architectural concerns I should address early?
- Community — Are there other tables in your deployments that reference
obsthat I should handle during archiving? Any restoration scenarios I haven’t thought of? - Everyone — What would make you actually trust and use this feature in production?
CC @dkayiwa , @samuel34 , @mherman22 , @ibacher , @wikumc , @jayasanka , @jnsereko , @chibongho, @dkigen, @raff , @icrc.psousa