There’s some very good important work coming together on how we will use the Cohort Module to support patient lists. The O3.0 UX designs call for distinguishing between System Lists and User lists. See Zeplin - Projects.
I’m not sure we have exact consensus on the definition of a a System list. Examples of system lists might be a service delivery queue, a list of patients who missed their appointments, etc.
A User list would be one created and managed by a user.
One way to label the list would be using the CohortType. Another would be to use a CohortAttributeType. Or perhaps introduce a new column into CohortType allowing this to be defined? The last feels awkward to me especially because what do we do if want the permitted values to change over time. Does anyone have recommendations on the best way to do this?
On a separate but related note, @samuel34 would like to introduce a new feature which allows one to define a set of cohorts in which a member may only be permitted membership to one. The backend would automatically remove a patient from any other lists in the same set when added to any cohort within the set. He is experimenting with using the CohortType for this and would like to add a column to the table to do so. Please see here: Comparing openmrs:master...samuelmale:cohort_types · openmrs/openmrs-module-cohort · GitHub. However, perhaps this is best achieved by a CohortAttributeType?
I bring these two examples up because they clash. If O3.0UX is to depend on the System vs User categorization, then every list will have to have a type System/User (to be used properly by the UX) and would essentially remove custom types. The column introduced by Samuel would never be permitted to be active as this would essentially make it the case that a patient could only be in one list at a time.
Perhaps, we are using System List to ambiguously and we are better of creating multiple types within this category.
We discussed this with @burke and @ibacher the other day and we left it at the fact that system cohorts will carry some sort of cohort definition. That definition will point to a mechanism to calculate the cohort members based on business rules stated in the definition.
Then you could have an API method such as isSystemCohort() that will say true if there is a definition set for that cohort.
Usually types in OpenMRS are used to describe a clinical theme. I’m saying this based on how order, encounter and visit types are used. This is rather a rule of thumb of course, nothing that is set in stone.
As for @samuel34’s use case, it looks very custom. I’d do that with some advice in a custom module. The advice would watch for changes made on cohorts and apply the wanted effects wherever appropriate, such as the one you described, i.e. some kind of membership cleanup on other cohorts. If the business rule to identify the cohorts that need to be cleaned up is “same owning user + same type”, then ok so be it. That’s implementation specific IMO.
I have more to say with regards to the discussion of having the ability to specify unique membership but I will wait to hear others thoughts.
I’m still confused though by this description of a system list. Is a system list just a definition? Are there static members? If no members, then I think we’re missing a category in the UX designs. Because let’s say we have a list of patients waiting for triage. It’s not a “user list” per say (i didn’t create it). And it’s not a system list (it has members and not based on a definition). So what is it?
The UX designs were meant to distinguish personal lists from shared lists. Perhaps shared is the right term here rather than system.
I do think having system (i.e. runtime) lists are a critical feature but this wasn’t how I was interpreting the designs.
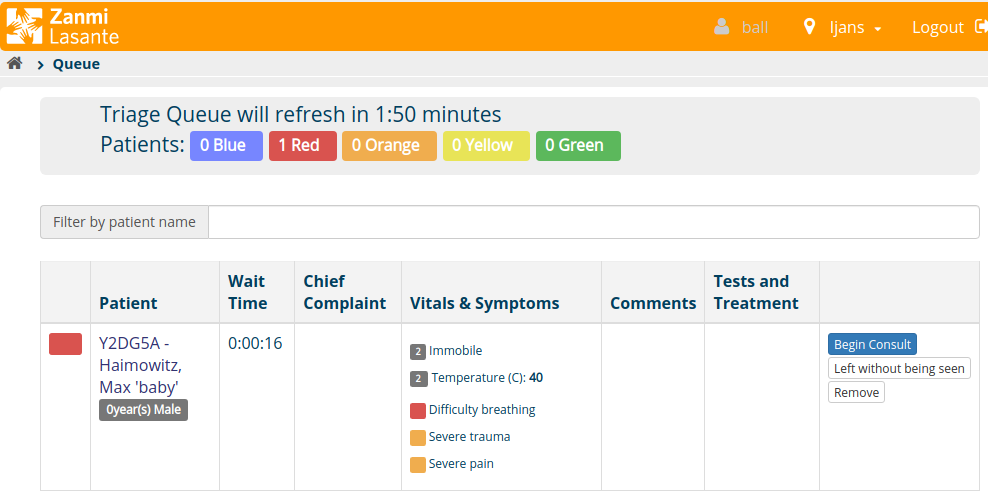
PIH has a custom module for emergency triage. Maybe this is beyond the scope of this conversation and design, but it would be great if this was more easily customizable and usable for others in the community. It’s an automatically changing patient list (cohort?) based on who’s in/out of the ED.
These sound like alternative names for what I believe Cohort Types was originally intended:
Static Cohort – manually defined
Dynamic Cohort – calculated from a definition
It would seem a user or the system could (eventually) use either/both of these types of list, so I’m not sure the names “System List” and “User List” are useful – i.e., not all user-managed lists need to be manually managed and not all system-generated lists need to be calculated (e.g., the “system” through an automated process could generate a static list).
I would suggest Cohort Type be used to distinguish between dynamic (aka calculated) vs static (aka manually managed) lists and address ownership/access separately.
Complicated business rules around sets of lists sound like a specialized use case and might be better implemented on top of cohorts – e.g., allow a module to subscribe to changes on specific cohorts, which it could use to apply its business rules. Is this capability being discussed somewhere?
To me, a Cohort Definition is just that - a definition for how to compute a Cohort. One such definition could be “a specific saved set of patients”. This is how the reporting module sees things - see: StaticCohortDefinition.
In the reporting module, an “EvaluatedCohort” is essentially a cohort that has additional references back to the definition and the context that was used to compute it. So this could be used to a similar purpose as “CohortType” in that you can inspect the CohortDefinition’s class or interface or some other marker to determine if it is “dynamic” or “static”.
Overall, I think it would be helpful for us to step back and look at the different places where we have built out Cohort-related functionality, and to come up with a future-looking vision for what we want to support and where. Among those places should be:
The OpenMRS core notion of a “cohort” and how this has evolved from a static list of patients to one where cohort “memberships” are optionally date-constrained
The OpenMRS reporting module’s Cohort Definitions and how these definitions are stored and categorized and how these relate to core Cohort.
The OpenMRS cohort module, and how it has evolved - what use cases it was originally designed to address such as “household” cohorts that can have Obs and Encounters associated with them, how general-purpose it is, etc.
It would be great if we could lay out a vision for how we would ideally like to architect things, and then see how each of these approaches fits (or doesn’t fit) into that vision and how each might need to evolve to contribute directly to it or at least ensure compatibility down the road.
Before we commit too far to how fundamental the cohort module is to the OpenMRS 3.0 product architecture, or how much we want to continue to indefinitely support the OpenMRS reporting module in it’s current form, I think it would be helpful to lay this vision out a bit more clearly.
@mseaton last time we spoke about this with @burke and @ibacher (not sure if it was a TAC or an O3 design call) we left it at the fact that calculated cohorts would rely on the Reporting module actually. Since the Reporting module already offers ways to define cohorts, and then calculate (evaluate) them.
… while static cohorts would be done differently, but that was in oblivion of the StaticCohortDefinition existence and possibility. Now it looks like that everything could go through the same Reporting module channel?
@mksd Seems a bit redundant, though, doesn’t it? We talked about leveraging the reporting module to build a cohort (as a list of patient ids) and then translating that into a cohort module / core cohort and serving that to the frontend. I get that we’d get some consistency, but it seems silly to leverage the reporting module to get a list of patients to translate that into a cohort when… we could just already have the static cohort setup (we also avoid the overhead of having to update the StaticCohortDefinition every time we update the cohort itself).
@ibacher sure maybe, I’m not close enough to the code of this cohort module to weigh in properly. Indeed I was seeking consistency and that may be overkill. However since there would be some kind of mappers to go from the Reporting module’s cohort datasets to that module’s cohorts, this shouldn’t matter too much in principle though. But again, I don’t feel strongly about this.
Use of dates is optional. A cohort service that accepts period of membership or can answer “who was in the cohort on YYYY-MM-DD” can be used like a list of people and the dates ignored.
Great point. Example is static via dynamic as definition rather than “type” discriminator. FHIR is using “type” to specify the type of members in the cohort anyway (meaning we probably shouldn’t be using cohort type for another purpose).
Some of the features of the cohort module are worth keeping and others could be removed and brought back again some day. More details below.
To ensure we’re evolving toward FHIR (not diverging or creating new incompatibilities with FHIR), let’s start with what FHIR Group offers:
FHIR Group
property
description
notes
active
active / inactive
All cohorts will be seen in FHIR as “active” until we decide we want/need to add the capability to disable cohorts (without voiding/deleting them).
actual
“actual” list of people vs. “descriptive” list of “types” of intended individuals
From the documentation, I’m not sure FHIR’s “actual vs. descriptive” is precisely our static vs. dynamic. But maybe. This seems like a FHIR property we could infer when exposing an OpenMRS cohort as a FHIR Group.
type
kind of members (e.g., people, cows, syringes, etc.)
We can focus on people and leave grouping of cows & syringes to farming and inventory systems.
managingEntity
ownership
We’ll want to have owners, editors, viewers.
characteristic
a simplified set of key/value pairs defining include or exclude criteria
This looks like one approach to a cohort definition hardcoded into the FHIR group. We need more flexibility.
member
members are anything (people, cows, syringes, etc.)
We’ll focus on people.
member.active
active / inactive membership
For FHIR, we would infer inactive for any member who doesn’t have a membership with start & end dates covering the time of interest.
member.period
period of membership
Same as our membership start date & end date.
Next, let’s consider what we have in core:
OpenMRS core
members are patients
period of membership (start date & end date)
And then there’s the Cohort Module (wiki page), which was initial intended to enhance our cohorts in a way that could be re-introduced to core:
Cohort Module
members are persons
cohort attributes
membership attributes
membership role (e.g., head of household)
obs, program, visit & encounter for cohorts
So, let’s imagine bringing these together into a way that helps align us with FHIR and focuses on the things we need now (e.g., we need to support patient lists asap):
Target state (what we want now)
Use cohort definition to define how cohort is determined
Doesn’t translate to FHIR Group (which only supports include/exclude list of key/value pairs)
Support attributes of cohorts & memberships to empower local & module needs through extension
property
notes
cohort.definition
Take the reporting approach of providing a definition of how a cohort is achieved. The definition might specify the cohort is manually managed or it could point to a handler that can return the cohort. We’ll probably want a definition_handler property to avoid having to pre-define all types of definitions; rather, have the API persist the definition and where to go to turn the definition into an actual list of people. The API would provide common use cases out of the box, but custom cohort-generating algorithms with their own definition schema could be supplied by add-ons.
date_members_updated
The UTC timestamp of when the cohort was last updated (whether manually or through a calculation)
public
Some mechanism to support visibility (e.g., public vs private)
ownership / access
Like FHIR has managingEntity, we want to track ownership. We’ll want more than ownership; rather, we want to be able to relate users to a cohort with access levels (e.g., owner, editor, viewer).
cohort.attribute cohort_member.attribute
Attributes allow implementations and add-ons to innovate without having to fork the code. So, I would favor supporting the OpenMRS attributes pattern for both cohorts and cohort memberships.
cohort.type == Person
We should probably migrate away from using cohort.type for other purposes (e.g., static vs. dynamic), since FHIR defines their type as the type of members. In our cases, this will always be persons – not just patients (like we currently have in core), but not cows (like FHIR supports). The idea of static (manually managed) vs. dynamic (calculated) cohorts can be absorbed into support for definitions (since these are definitions of how the cohort is realized).
cohort_member.start_date cohort_member.end_date
We continue to support periods of membership. The API is (or can be) designed so cohorts can be used as a simple list of persons and the start & end dates ignored if they aren’t needed.
The type of contract with a definition handler could be include methods like:
public interface CohortDefinitionHandler {
boolean needsUpdate(cohort); // True if cohort needs to be updated
void update(cohort); // Update cohort using definition
boolean supportsManualChanges(cohort); // allow manual changes?
}
This means we put the obs/program/visit/encounter for cohorts along with membership roles aside for now (pull them out of the cohort module) and focus the cohort module on cohorts of persons, user access to cohorts, cohort definitions, and continue supporting cohort/member attributes. This would allow us to support most/all of the needs for OpenMRS 3.0’s patient lists.
Future state
Add membership roles
Add membership sort weight
Support obs, program, visit & encounter for cohorts (like FHIR does) in core, so reporting and the rest of OpenMRS API can leverage them
I haven’t addressed this requirement – i.e., mutually exclusive cohorts. I’d suggest we could work through design ideas for supporting mutually exclusive cohorts in a separate Talk topic.
I don’t know what you mean by this. The “StaticCohortDefinition” is just a simple thing that points to an existing saved, named Cohort.
I’m not saying using StaticCohortDefinition is necessarily desired, I just wanted to point out the the reporting module already has an interface / class structure that both abstracts away the notion of whether a cohort is dynamic or static, as well as providing a means to determine if it is static or dynamic (i.e. if it implements StaticCohortDefinition).
I tend to shy away a bit from mapping voided directly to a FHIR-readable property. The reason is that the FHIR module generally treats voided content as if it were deleted, so that, e.g., every visible cohort would necessarily be active. If we have a reason for differentiating active from inactive cohorts, then we should probably create a property for that purpose (so that the semantics of voided/not-voided are consistent across the domains rather than domain-specific).
I would agree with @ibacher here. It would seem to me that our closest current analog to “active/inactive” is the membership startDate and endDate. A member is inactive on a given date if the startDate and endDate indicate as much, and a cohort is inactive if it has no active members. But we probably want a new property for this, or to adopt a Cohort attribute for this.
Fair points. We can infer “inactive” for cohort memberships that are outside of their start/end dates. For cohorts, we can just have all cohorts “active” when exposed via FHIR until we decide we want to support disabling of cohorts (without deleting/voiding them).
Catching up on this discussion, so apologies if I don’t get this right. I think FHIR is a good model to shoot for, but it is primarily for transfer of cohorts and not creation of cohorts. We need to think a bit broader about what a cohort is and how we create one. For example, access to patients to calculate the cohort determines the membership. If the cohort was built with one level of access (perhaps I don’t see HIV+ patients or certain private patients) then my cohort denominator will be different from another’s. So privacy or access needs to be captured somewhere.
The actual property is sort of like intensional and extensional value sets. Actual is a list of patient IDs (like a list of codes) and descriptive sounds like it is a rule-based description which requires evaluation to generate the members (like “all children of a particular code”). In the case of extensional or descriptive cohorts, you need enough information to evaluate/expand the list. That includes denominator, date of the rules, dates of the data and the date the query is executed.
For example, I might run a query looking for all people who had a CBC between 1.1.2021 and 3.31.2021. I create that list of patients today. Tomorrow, data is added to an existing patient in the database adding a result that occurred on 2.1.2021. If I re-run the cohort, I will add a new patient to the cohort even though the date range did not change. Somehow we need to capture not only the dates we are interested in, but also the date at which the cohort was evaluated (for dynamic/descriptive cohorts).
The cohort.definition would contain the information needed to evaluate the cohort, including date ranges of concern when appropriate. The specific format & content of the definition would be determined by the handler/type of definition. We might want to include some basic cohort definition handlers within the Cohort Module, but wouldn’t want the Cohort Module to try to define all the possible ways a cohort might be defined.
Good point about needing time last computed. I’ll update my earlier post to include that.
The near term goal for cohorts is to clean up the Cohort Module to focus on the foundational features needed to support our near-term cohort & patient lists. I’ll try to work with @ibacher and @corneliouzbett to define and share a near-term strategy for the Cohort Module.
I think we have two kinds of date_updated that are relevant here: the last time the Cohort itself was modified (for whatever reason) and the last time the Cohort definition was executed. The latter can be stored in an attribute and read by an appropriate handler or some similar mechanism. But we wouldn’t want to confuse things by claiming that the cohort was last updated two minutes ago when all I did was tweak the name or similar.