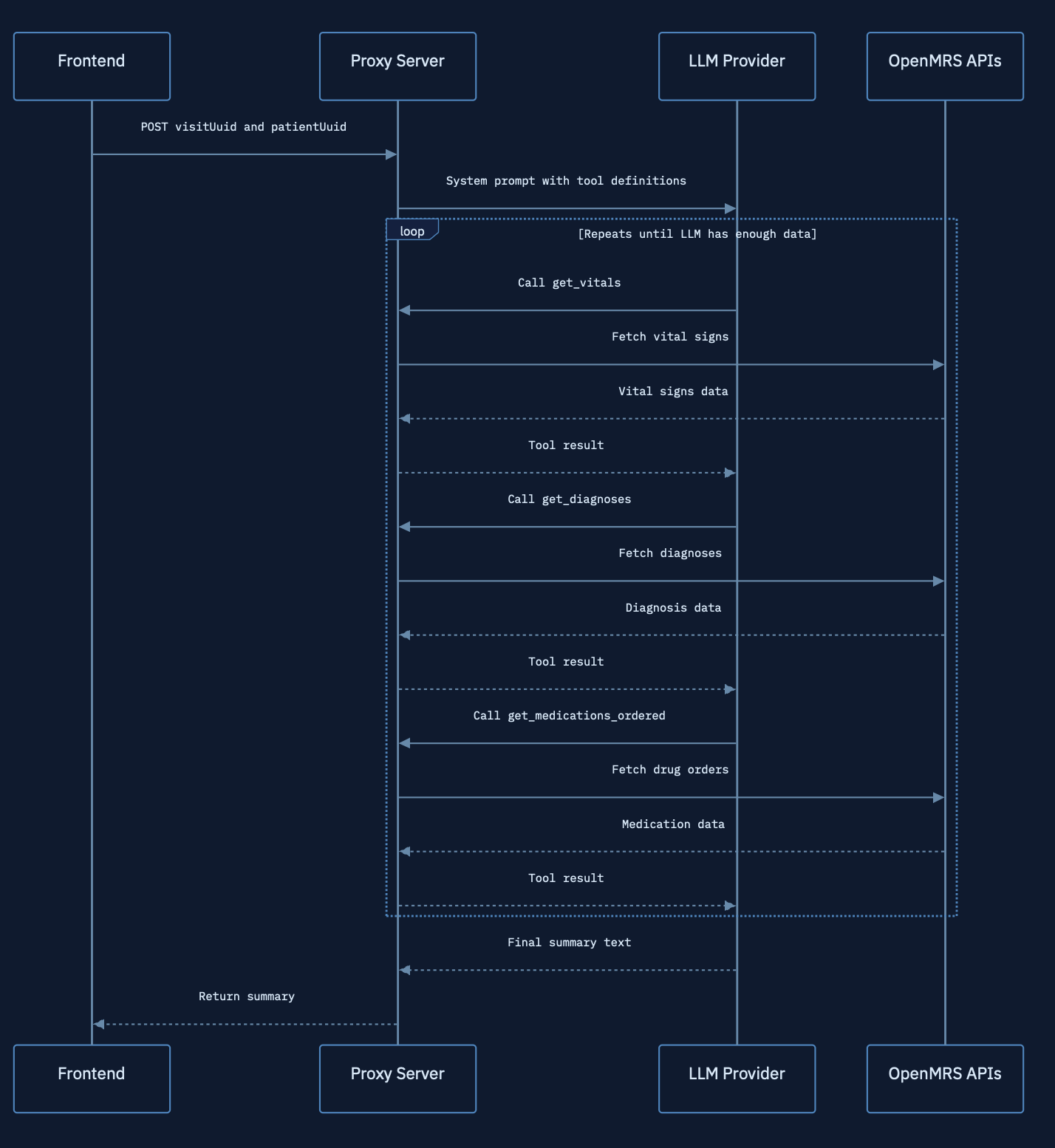
I’ve been playing around with how we can bring AI into OpenMRS, and built a prototype that generates a structured visit summary using an LLM.
Basically, the users would be able to launch the summary generation workspace from the visits table which triggers a call to a proxy server.
The proxy server is a ExpressJS server, which, based on the endpoint, has a system prompt which hands the LLM a set of clinical tools and tells it to fetch the data it needs from OpenMRS — vitals, diagnoses, medications, allergies, presenting complaints, and more.
The LLM produces a structured, readable summary of a given template that the clinician can review or regenerate. The summary can also be printed as a PDF directly from the workspace.
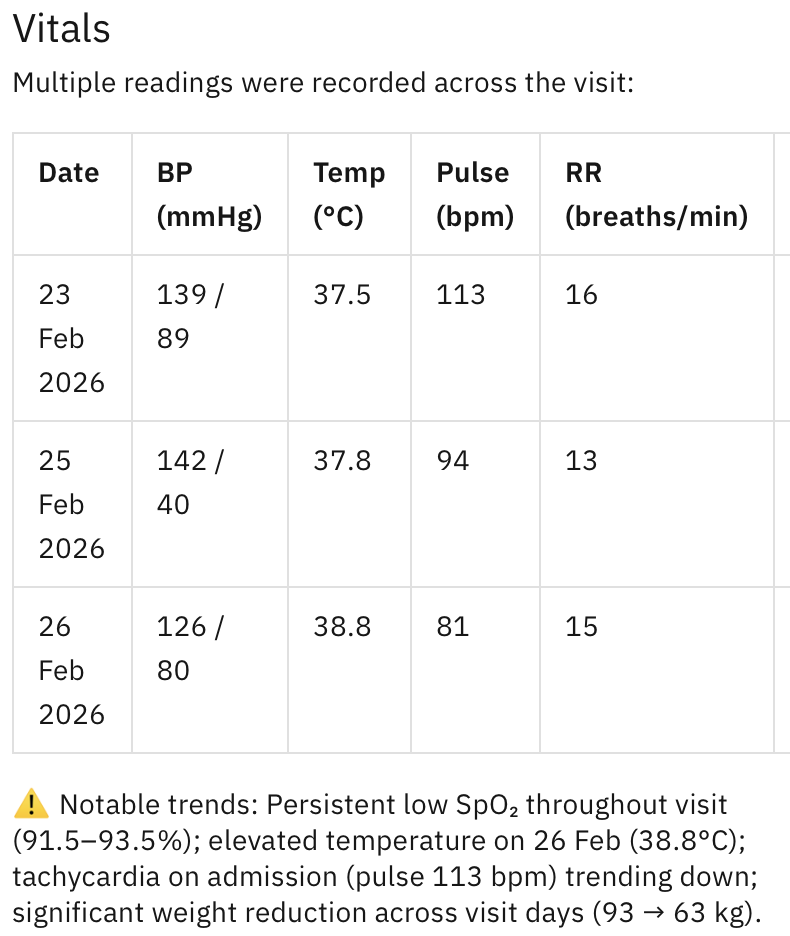
What I found cool was that, if you test this out on the demo data of the patients, it can flag out things to look out for, even when it wasn’t explicitly prompted to do so. Here are some examples:
I think what I’m especially impressed by is the amount of stuff this manages to do with a fairly simple, straight-forward prompt. Wonderful work @nethmi!
Not necessarily, it uses whatever LLM its configured to use. So it can be configured to run with a locally running LLM, or given the API key to an external one.
This is really impressive @nethmi! So nice to see these sort of experiments.
Re: local models, the following seem to handle reasoning quite well with small resources like around 4-8GB RAM. Could be interesting to try some of these and see how they perform.
Hi @nethmi, nice project and direction for OpenMRS!
A couple of questions:
On local models, same as @dkayiwa asked, have you tried running it with smaller local LLMs? It would be interesting to see latency, hardware requirements, and quality compared to external models. Indeed, many OpenMRS deployments may prefer local models due to connectivity, cost, and data governance.
Echoing @akanter’s question about patient data, how are you planning to handle PHI when using external LLM providers? Are you considering a de-identification step before sending data to the model?
Finally, a boarder architecture question, would it make sense to introduce an “agentic-openmrs” service/container in the distro Docker Compose to centralize shared AI features (LLM proxy/routing, local models, de-identification, prompt management, etc.) following privacy & security best practices and that could support projects like yours?
Re external LLMs, some of the large companies have secure access portals with technology and service promises to protect patient data — OpenAI on regulation-compliant Azure, for example. We see an increasing number of hospitals worldwide (other than EU, which has been very strict so far) making use of these platforms, although they avoid sending names, birthdates, etc.
OTOH many of the smaller self-contained LLMs have performance that equals the big companies with about a nine-month lag. So these can provide performance that you would have considered state of the art only a little while ago.
Great work, @nethmi This is a really good direction for bringing AI into OpenMRS workflows. The structured visit summary and the ability to flag unexpected insights from demo data looks promising shows real potential for clinical decision support.
A few thoughts on next steps and areas to explore Offline / low-connectivity use cases Since many OpenMRS implementations operate in areas with limited or intermittent internet, it would be valuable to explore how this prototype could work offline. Have you considered Running a lightweight LLM locally ? Caching patient data locally to reduce dependency on real-time API calls?Designing a queue system that generates summaries when connectivity is restored ? something like kubernetes infrastructure ?
Thanks @akanter for pointing this out . Since most AI models generate responses based on what you prompt them with, it’s always critical to add a layer that ensures patient-identifiable information is not pushed to the AI. This can be addressed in the script itself, for example, by anonymizing or filtering data before it’s sent.
Another approach is running the model offline to ensure data remains local at the clinical level. Some AI models can be deployed offline and even trained locally on OpenMRS data, which would keep everything within the facility’s infrastructure.
There may also be opportunities to bring together existing work in this space, combining insights from what’s been built here with expertise from others who have tackled security and offline deployment to help support and scale scattered efforts across different teams
One of the things that would be helpful input from the community is the type of de-identification or anonymization that would be useful or necessary. Something like this does involve sending data to a model, but, e.g., patient demographics are pretty trivially censorable in this setup (the only information initially passed to the agent is a patient UUID and visit UUID; other data is extracted from the EMR via tool-use, which gives us a pretty clean hook to do whatever kind of sanitization is necessary).
Technically, it wouldn’t be difficult to make the dataset match HIPAA’s “Safe Harbor” standards, e.g., don’t send any dates or send only munged dates (i.e., start the visit from a random date in the year, shift all dates to match the time from the “real” start time to the “fake” start time) or addresses, send only an age category and add a bit to the backend service so that instead of supplying patient and visit UUIDs (which are technically patient identifiers), we generate per-run tokens that are processed by the LLM and “translated” in the backend service to the actual UUIDs for the calls to the APIs, then ensuring that those UUIDs are omitted from the response sent to the LLM.
Technically, the above would produce a data set that matches HIPAA’s “Safe Harbor” rule, though, in practice, most US-based hospital systems would probably reject that without additional safe guards. Thus, this sort of POC may not be acceptable to most organizations without either local LLMs or some kind of provider with regulation wrappers (several vendors do sell nominally HIPAA-compliant access to LLMs).
It probably does. And I think part of the exercise here is in identifying what kinds of “stuff” needs to be in such a service and how it should be packaged. Do we run it, like this, as a separate service or integrated as an OpenMRS module? What tools and capabilities does such a service need to provide?
Most likely whatever we do here will be independent of actually loading and running local models (their are great tools to do that already and where possible we usually want to adopt existing tools rather than building our own), but certainly there’s scope for managing settings and parameters that are controlled via requests to those models.
Offline is one important component to explore, but there’s also a lot of just baseline functionality we need to think through too. And in some ways, it’s easier to iterate by taking this in pieces, e.g., one stream might be looking at just the core agent loop, tools, and data censoring / API privacy considerations, another stream might be thinking about how this connects to local or at least non-cloud-hosted technology and what kind of resources are necessary to run a minimal model with the capabilities we need, yet a third stream might think about how this all works in the absence of internet technology. But I think that bashing those three streams together is probably a recipe for us not making a lot of forward progress on any of those parts.
Sounds a good Idea, initially had thought of coming up with some sort of template that’s highly configurable, that provides a basic setup for both backend(AI) and esm related funstionality such that folk do not have to start from scratch everytime, the ony thing they would do is to determine which architecture to use either RAG, MCP or directly via a certain SLM / LLM of their choice. But at the core being able plug into the OpenMRS context and do whatever business they desire. We could discuss these on the upcoming AI call. it’s just that 3.6.0 Release has been top most on people’s minds currently.
Broadly speaking, I think we need to provide a configurable list of options, and if it’s a template, we need a default list from which a user can pick out of the Box, for example
I have come across this thread-again-with guidance from Andy. This topic has been of deep interest since my days in Hopkins. It has become relevant since I delivered a presentation on OpenMRS as a Global Good, in Perth, in March. Several days ago, I was invited to present at a Digital Health Festival in May 2027. The organisers would like me to expand my presentation to include developments like this and other AI functionalities. It is wonderful to still feel I am contributing.