Hi Everyone,
I’ve noticed some gaps in our process that I would like to propose a solution to, but would first like to discuss my philosophy here. Let’s first think about what philosophy best fits our community, and that can help structure arguments over how and if we should adapt our processes.
Situation:
Our development process currently goes something like this: A developer pulls the latest code locally, develops on their machine, makes a PR, and after approval this is merged into ‘main’ or ‘master’ branch. Anytime a PR is merged this code is automatically incorporated into the dev3 instance (https://dev3.openmrs.org/ ), which has the benefit that anyone can instantly see it, but also if some fatal bug is accidentally introduced now dev3 is broken for everyone. From there we have the option to manually create a ‘version’ on a per-repo basis. This step has not been done in almost 3 months. This newest version updates npmjs.com and becomes the ‘next’ package as well as a stable identifier (i.e. 3.2.1-pre.1149). Next, O3 (https://o3.openmrs.org/) can be updated manually via the “release” stage of the CI build, which is set to build with whatever the “latest” version is. Because this process is run manually there is some control over what ends up on O3, although since there is no testing before a release is cut the quality is not guaranteed, is usually ‘yellow’, and most of the time is in fact not known. Also we are unable to answer “what features are on O3” without looking at the release notes (hopefully it is documented there) for each individual package. Currently even this minimal process is not being attended to and O3 is almost three months behind dev3. O3 being out of date and ‘not very stable’ is often frustrating for those using O3 to demonstrate the capabilities of 3.x product to prospective clients.
In summary, currently we have a process which seems geared towards “move fast and break things”, and I would say even so fast we don’t know (or at least I have a hard time answering) what features have been implemented and whether they are working or not. Because there is no quality documentation the community relies heavily on asking one another what is working which is poor because it is 1. Slow, 2. Limited by that person’s understanding of the product. 3. Information will be missing because the feature set is so extensive.
Ideal Process Qualities:
This is the important part. Please disagree with me here or add additional requirements. Also, to preface, yes some of these are already existing. An ideal process should be able to do the following things:
- Allow developers to constantly develop new features and bugfixes (Dev)
- Have a stable production-level showcase site (Demo).
- Versioned reference application (RefApp) which can be tested for features and quality on an instance which is isolated from Dev and Demo (Test)
- Ability to select specific releases of each repo to include in a RefApp version.
- Ability to select a stable RevApp version to promote to Demo.
- Ability to make hotfixes to RefApp on Test in order to improve stability before promoting to Demo.
- Ability to ‘roll back’ a Demo version to a more stable one if desired.
- The RefApp deployed on the Demo should at all times have a known list of features and flaws
- Publicly available historical RefApp quality records to globally show when features and bugs were introduced.
- Constant release cadence. Releasing from dev to test once a week or more, releasing from test to demo once a week.
- Streamlined process allows ultra fast releases- Ability to release a new feature from Dev to Test to Demo within an hour. (or as Flickr says, “10 full releases per day”)
- Tight Develop-Test cycle. Bugs are found soon by testing and brought back into the ticketing system.
- A process which people will actually use.
Proposed solution:
Through all of the above I am hinting towards the need for a third deployment site which we can call Test. This will be isolated from fast moving Dev so that the package of packages is stable long enough to test, and also isolated from slow-stable Demo since candidate versions on Test might fail a quality check, and then not be desired to be promoted to Demo.
How it works:
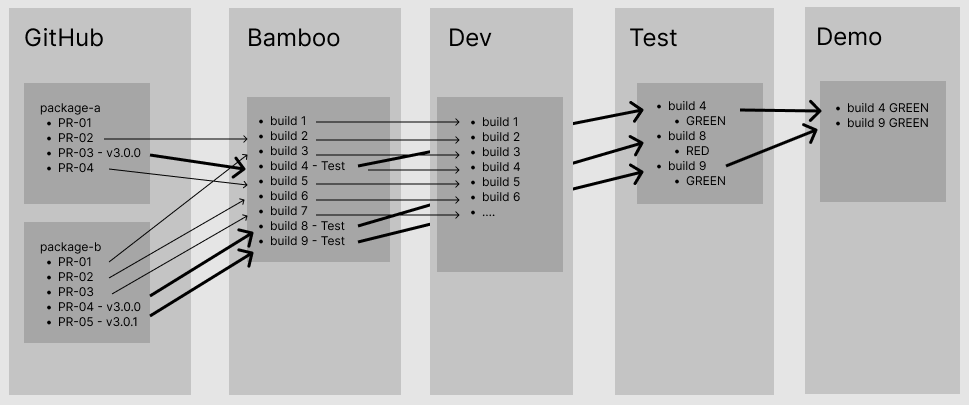
- PRs and merging work as before. All merges result in an update to Dev instance.
- Versions are made manually as appropriate. Depending on the cadence it is allowable to have several versions of a package released per day.
- When a version is cut npmjs.com gets updated, and this can immediately make a CI Docker image.
- GAP- It should be possible (for the purpose of hotfixing) to manually select the versions of each repo to include in the CI image. With our current setup I’m not sure how this is possible.
- Images are available to promote to Test
- An ‘Evaluator’ - (QA, Developer, Product Management, Business Analyst) - chooses an image to promote to Test. They either run a quick Smoke Test (10 minutes), a Change Test (10-30 minutes), or a Release Test (1 - 5 hours). Notes from this test are kept on the community Wiki
- If a Test fails the quality check then packages which are causing errors must be updated either on the main branch or a new release branch, versioned, and promoted to Test again.
- If Test passes the quality check we can then promote this image to Demo.
- If some bug is later found on Demo it is possible to redeploy an older image (and we have documentation to know which are good)
New Dependencies:
This new process requires new dependencies:
- Test environment
- Storing release images in Artifactory
- Testing
Who is responsible for testing?
For now community volunteers. This is an interesting topic to support for anyone who wants testing to be done. I’m signing myself up to start the first couple releases because I want to learn more about the product and be able to effectively communicate status and trajectory to stakeholders. The Product Owner (Grace) generally has a lot of interest in this being done so they can know the state of the Demo and prepare properly. Anyone who is selling or implementing this product has an interest in knowing which versions are stable. Testing the app is a great way to quickly introduce the app newcomers, interns, fellows. One interesting process we can try is to have a rotating duty where each developer will be responsible one week for testing. There is hardly a need for a full time dedicated staff here, although maybe as the process matures one testing expert can be available ¼ to ½ full time to do testing activities and be available to mentor anyone interested in helping with or learning about this process.
I think having both a Test environment and the quality assessments will help us have an up to date and stable Demo environment, help us quickly visualise product feature implementation and health, and quickly spot and fix bugs. The transparency will improve team alignment, act as a tool which can guide conversations, and lead to a much improved onboarding experience.
Please let me know your thoughts. Thanks,