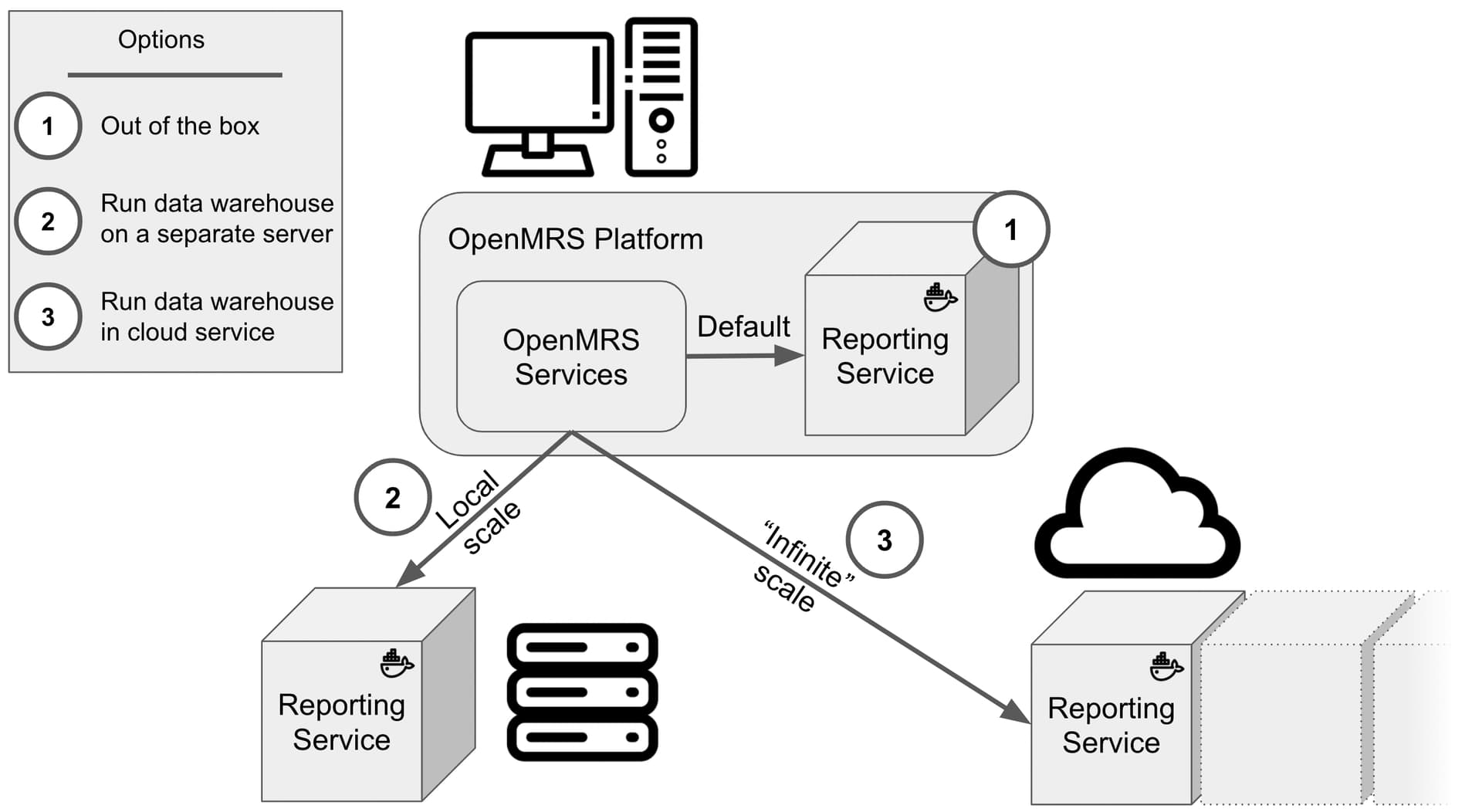
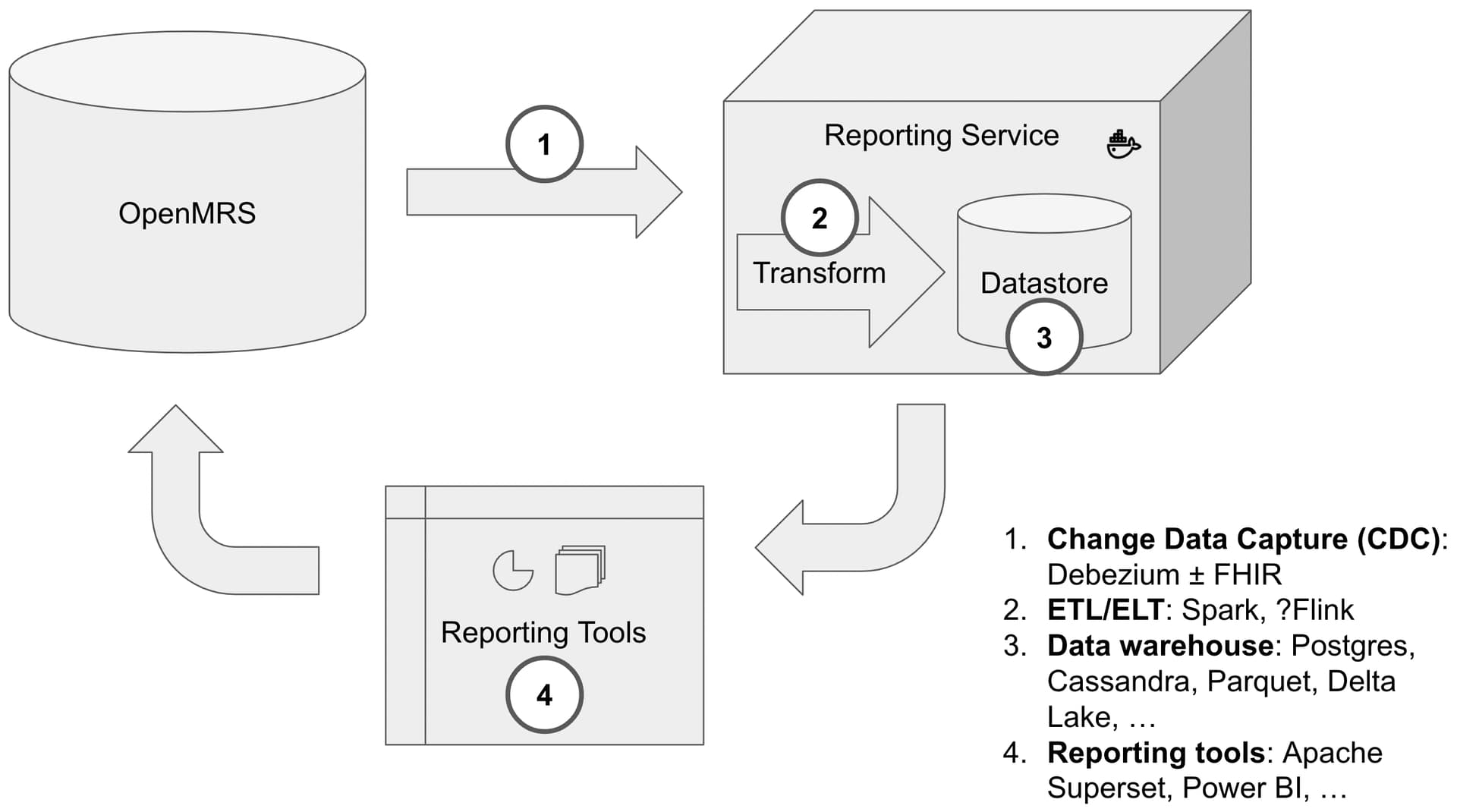
There’s been a lot of work by the Analytics Engine Squad on openmrs-fhir-analytics; however, standardizing on a FHIR-based schema with its long term benefits has limited its utility/adoption in the short term (e.g., for other orgs like PIH, UCSF, Mekom, etc.). PIH has been using PIH’s ETL framework petl to feed Microsoft Power BI, but @mseaton has recently been diving into reporting strategies, including the work @akimaina did in his openmrs-elt repository, and has broken it down into four areas:
- Change Data Capture (CDC) and event streaming. Debezium is lighter weight and runs better with limited resources compared to Kafka/Connect, Flink conectors, or bespoke Java code.
- Data processing pipelines and Extract Transform Load (ETL). Spark with Python or SQL vs. Flink with SQL APIs.
- Analytics data store. Lots of possibilities like Cassandra, Druid, and Parquet (with Delta Lake, or maybe with Hive), ElasticSearch, as well as services like Trino that provides an ANSI-SQL interface where one otherwise didn’t exist (e.g., it enables querying Elastic Search with a normal JDBC client, with other benefits). AMPATH has had success with Cassandra (with some limitations).
- Reporting tools and BI. Considering Apache Superset, while being able to use tools like Microsoft’s Power BI.
While we certainly won’t be able to cover these in detail during a 1-hour TAC call, we would like to devise a strategy for technically-minded folk trying to create reporting/analytics solutions from OpenMRS and organizations desperately looking for a way forward with reporting and needing to make near-term decision to align or at least be moving in a shared direction.
Agenda for this Monday (31 January): Reporting Strategy for 2022
- Brief overview (where we are with reporting today, near term needs, and longer term goals)
- To what extent can we align reporting efforts?
- How can we get to a shared vision for advancing reporting for OpenMRS in 2022 that yields near-term benefits for immediate needs and points us in a direction of building shared assets for reporting?
- Do we expand the scope of the Analytics Engine Squad? Or have a smaller team (alongside @akimaina & @mseaton and “OHRI reporting” dev(s)) working separately? Or is there another approach to take?
Where: om.rs/zoomtac
When: Monday at 3pm UTC / 7am PST / 10am EST / 4pm CEST / 6pm EAT / 8:30pm IST
/cc @akimaina @mseaton @mksd @jdick @eudson @ibacher @mayanja @mogoodrich @ssmusoke @grace @raff & please CC others you think would be able to help us in a shared strategy for advancing OpenMRS reporting in 2022