Using a NoSQL data store will fix this particular problem (adding new columns fast) but will create others (complex queries for instance).
It’s not a silver bullet.
Some people maintain two stores, one relational and one NoSQL that must be synchronized (queues, scheduled ETL processes …).
I’ve read the Uber article and it’s interesting, however I don’t think they modified MySQL, they built something on top of it. I don’t know why they didn’t pick up an already existing solution that provides sharding.
The Bahmni is going to prioritize adding obs.interpretation (and we’ll also add obs.status, per @burke’s suggestion). We really want to do this in Platform 2.1.0, which should be released this month.
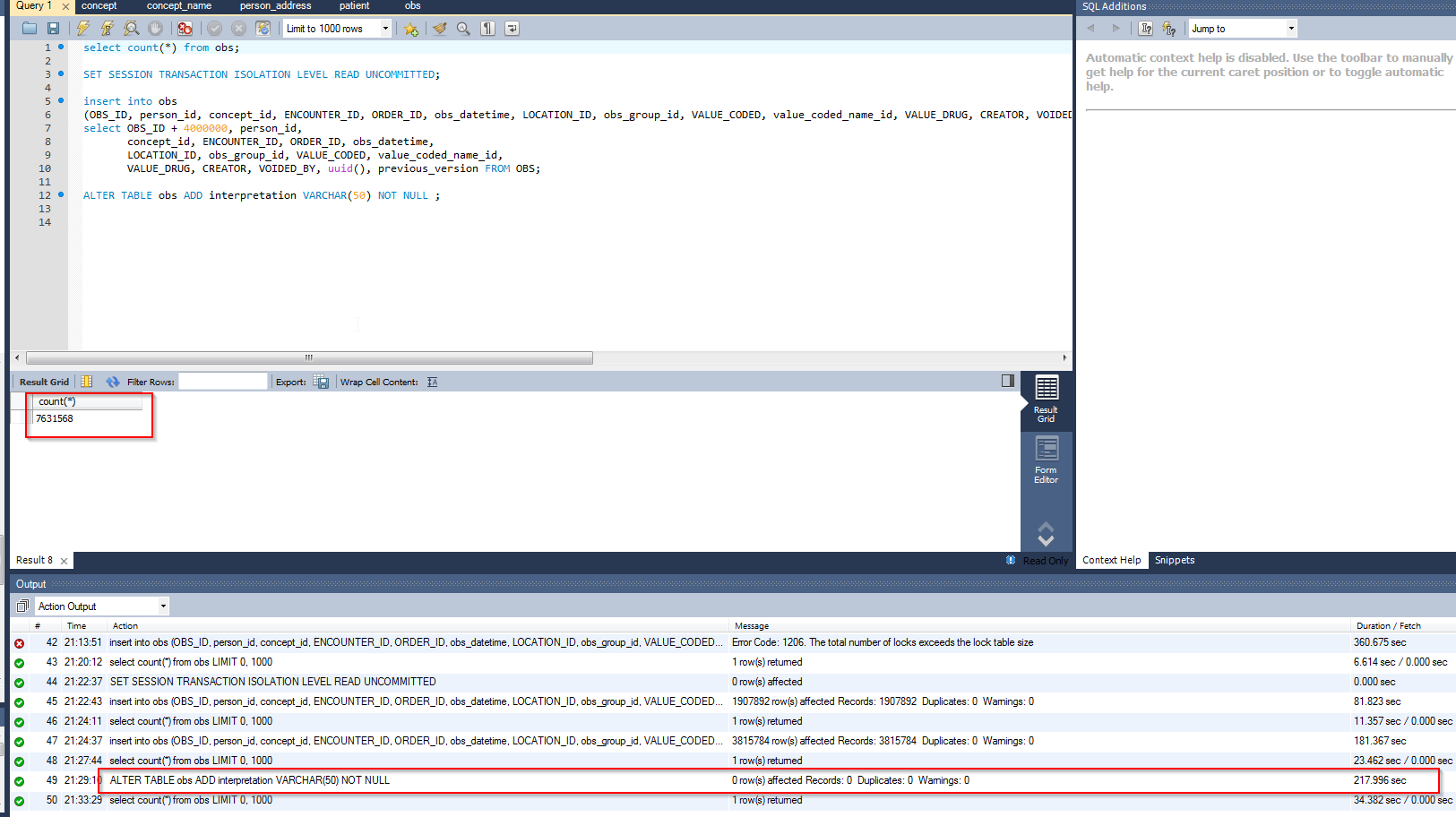
@jdick can you prioritize testing whether the Online DDL feature in modern MySQL will allow this change to happen smoothly for an AMPATH-sized database?
(I have also asked @teleivo if he might have time to test this, or perhaps @lluismf is interested. But really this is a huge issue for AMPATH, and we need AMPATH to be involved in testing the solution.)
I think a sufficient test is as easy as:
Install OpenMRS on MySQL 5.7
Populate a large obs table (by script or something)
Manually execute “alter table obs add column interpretation varchar(50)” and check whether you’re still able to use the OpenMRS UI while this DDL is running
I am not sure why I didn’t see this sooner. I don’t work for AMPATH anymore but when we were upgrading from 1.9.7 to 1.11.6 we used a technic similar to what you have asked about. It is found here . I believe the technic can be modified and included in a generic upgrade module as suggested by @burke
My understanding, then, is that it’s okay to make certain kinds of changes to the obs table in new releases, because there is a proven way for an implementation with a huge obs table to upgrade.
It would be nice to also automate the upgrade process for implementations with huge obs tables (and maybe the latest MySQL versions can handle this even easier). Since there are only a few implementations this applies to, I propose that the next time one of them is doing an upgrade they should collaborate with some OpenMRS community developers to build out a standard set of scripts for applying data model changes pre-upgrade.
Thus the Bahmni team can start to work on TRUNK-4976 because it’s not blocked by this particular concern.
(The ticket is still not ready-for-work for a different reason, because there’s an open question about the obs.status column.)
If for some reason the ALTER TABLE doesn’t work, there’s this tool created and used by GitHub staff:
Please read the Readme, they use a pretty clever technique to achieve it. But IMHO to just add a new column it shouldn’t be necessary. I guess this is intended for big schema changes.
can we get more details on the AMPATH implementation and the test
MySQL version?
the AMPATH wiki page says 90 million obs in 2011, how many do they have now?
I assume AMPATH has its own distro, what OpenMRS version/setup should we use to test it? Simply use openmrs sdk with reference application 2.3.1?
with ‘whether you’re still able to use the OpenMRS UI while the DDL is running’ do you mean if I can still add an observation like for example capture a patients vital signs?
My thinking was that we don’t have to answer “exactly how much work will it be for ampath to do this next upgrade” but instead “if ampath and other large implementations do a (possibly large) amount of work to get on the latest version of MySQL, can they then rely on a built in mechanism to add columns to the OBS table without taking their system offline?”
This seems like a quicker-to-test question whose answer tells us how much the OpenMRS community would prioritize building a custom devops approach to this, or if we can just say it’s a solved problem because MySQL.
Of course if you want to go further towards testing ampath’s exact upgrade path, don’t let me stop you!
I believe that building a custom solution is bad. The tricky part is, using the shadow table approach you can’t lock the original table and you can miss all the writes performed on it during the process. The github solution reads from the transaction log which is brilliant, and I’m not sure we can do that without a big effort.
Your narrative about what to include makes a lot of sense. You should have put it before the table so I didn’t start going row by row.
I think we should also support < and >. These aren’t the same as LL and HH, rather they are “Off Scale (Low/High)”, i.e. can’t be accurately measured by the lab machine. For HIV I remember it being an important use case (that we never got right) to record undetectable Viral Load for which the machine we had reported “<40”, its lower limit. (Though maybe in FHIR that should be stored in a different property? Viral Load “<40” is both “normal” and “off scale low”.)
You wrote that B and W can be replaced by U/D, but this isn’t strictly true, since up/down imply knowing the direction of change, whereas better/worse can apply to a qualitative finding. (This is nitpicking though. I have no use case for this and I’m not arguing for adding it.)
I agree. We never managed to implementing structured numerics (support for boundaries & ranges). While this isn’t really the “solution” for boundarries (off scale), it could help having LT and GT interpretations.
On the other hand, it might have a paradoxical side effect. For example, at AMPATH, for a “<50” result, we chose to store 49 in the value and “<50” in the comment. The value of 49 helps ensure that the value behaves like you’d want in aggregate queries (e.g., not included if you search for everything >=50) or decisión support rules. If we had the LT and GT interpretation, we probably would have stored 50 in the value, LT in the interpretation, and foregone the comment. The side effect would make “<50” behave more like “50” in most cases instead of like “<50”.
tl;dr I support including LT and GT interpretations as long as we continue to promote as best practice storing values just outside the threshold for boundary values (49 or 49.9 for “<50”) and putting the structured numeric string (“<50” or “<50 undetectable”) into the comment. Interpretations can add information, but shouldn’t be required to use the value (in this case, distinguish between “50” and “<50”).
I agree with your concept of B and W but will continue to advocate for leaving them out, because labs may not know whether any given result that differs from another one is actually ‘better’ or ‘worse’ (A hemoglobin change from 16 to 12 is ‘better’ if the patient has polycythemia and ‘worse’ if the patient was in a car accident). Thus, they usually don’t, and probably shouldn’t, make that judgment. I was also trying to find an example of a test that is qualitative and could be specified as better or worse, but couldn’t come up with one.
Regarding the off-scale marker: I see the point that off-scale (out of measurement range) is a good and distinct property. FHIR’s use of the “transitive verbs” <= and >= as indicators clearly indicates that they expect a number after the symbols showing the measurable minimum or maximum value.
I’ll take a different view from Burke regarding the main result, though: the main result should be unspecified (we need a display convention like “*” or “TOO LOW”, etc.). This isn’t unique to this case: there are other reasons why the main result may need to be unspecified, e.g., a Potassium test that was unreadable because the blood was hemolyzed.
I’m not a fan of using 49 for “everything less than 50” – at some point when they change the assay boundary, 49 will look like a real value and be misleading. Real-world example: quantitative pregnancy tests used to stop at 25 mIU/ml, now they are more sensitive and stop at 5. All those non-pregnant women who had values of “24” posted would now be recognized as pregnant.
We had an example just like this at AMPATH, with viral load testing that started with sensitivity of <50 and later became <5. The historic values of 49 still work, since there’s no way to know if the value was 0 or 49 anyway. In your example, if you are going to consider women with a value of 24 as pregnant, then how would you know that the women with historic values of <25 weren’t actually pregnant? They could have all been 24s for all you know.
In each case, the comment contains the human interpretable value, so nobody should someone humans see things like
β-HCG (mIU/mL) 241
1 <25 undetectable
or
β-HCG (mIU/mL) 24 (<25 undetectable)
I’m not trying to suggest that this is the perfect solution; rather, if you have to put a value (as we do in the current data model) for numeric observations with a boundary, using n-1 (or n+1 for upper boundary) behaves close to what you expect if we could properly handle ranges & boundary values – e.g…, all your “<25” results will show up in searches for x < 25 but not in searches for x < 5, aggregate values (sums & averages) will be in the ball park (a dozen 100s and a dozen <50s would average to 74.5 instead of 50), etc.