Created a Pr with 3.x E2E login test. Please review the pr. cc @jayasanka @ibacher
Usually backend performance problems are DB related (in my experience). Bad SQL queries, misuse of Hibernate etc. These are relatively easy to detect and solve, no profiler needed. But I guess this is not the case, right?
No, you’re right that many backend issues, including likely in OpenMRS, are probably the result of inefficient database queries. That was just intended as an analogy to the type of knowledge necessary to troubleshoot frontend performance issues (which is really what this post is about), e.g., page loads that take >=1s.
2 Likes
p.s. - Worth noting the resources and approach the Bahmni folks are following, documented here. Performance Benchmarking and Capacity Planning https://bahmni.atlassian.net/wiki/spaces/BAH/pages/3038445574/Performance+Benchmarking+and+Capacity+Planning#like-section
Update from connecting with @eudson today about this:
- OHRI team is finding that performance in the OHRI demo is suffering so much that it’s causing need for weekly server re-boots and regular cache-clearing. (@larslemos @alaboso any additional detail you want to add?)
- Surprisingly though, performance seems better in the ohri.o3.openmrs.org combo environment. @larslemos is investigating why this might be. @ibacher when you are back from vacation next week, could you help with troubleshooting?
- @alaboso has been wondering why there’s a redirection to /spaa instead of /spa → Thread: _____
- @larslemos has discovered there’s a component taking too much time to load which is what’s causing the location picker to feel like it takes a long time to load -
New concern today re. cloud performance: @michaelbontyes has been trying to set up the O3 RefApp distro on an Azure instance (since he couldn’t get it working on his M1 as mentioned here). It seems like the frontend might be requiring >1GB. He is only using our default RefApp, using only the demo data, nothing extra.
Michael will try extending over 1GB and see if that resolves his issue. If it does… it means we have some clear memory performance issues to address. We’ll look forward to hearing your finding @michaelbontyes!
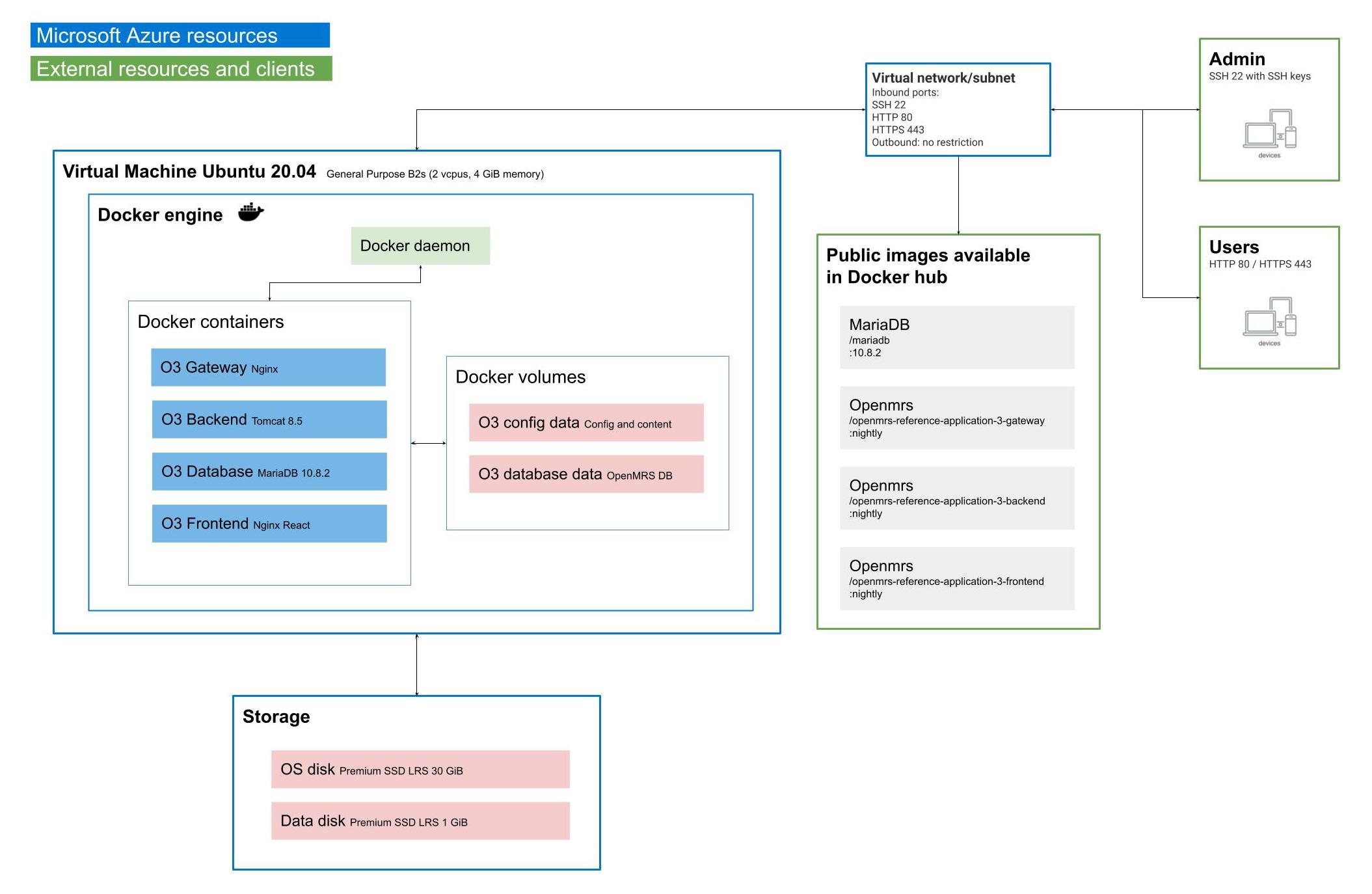
I am happy to report that upgrading the Ubuntu 20.04 VM from a 1 vcpu/1 GiB memory (Standard B1s) to 2 vcpus/4 GiB memory (Standard B2s) on Azure resolved the issue. I summarized the cloud infra in a diagram below.
I was able to run the initial setup within 10 minutes and the backend/frontend are now running and pretty stable. I didn’t do any load testing through.
1 Like
Thank you for this extremely helpful diagram & test @michaelbontyes!
Oy vey… @ibacher does this mean our frontend currently needs >1GB of memory? ![]() @raff @dkigen & @jayasanka any thoughts on how we could test/confirm this?
@raff @dkigen & @jayasanka any thoughts on how we could test/confirm this?
Reading the diagram everything is being deployed on the same VM thus sharing 4 GB of memory. I would say that is a minimum needed.
1 GB is definitely way too low to run backend alone. It needs 2-3 GB at least. The frontend alone should be good with 256-512 MB of RAM for thousands of active connections. Bandwidth will be more of an issue in case of frontend at that point.
1 Like
As @raff said, it’s actually the backend that consumes most of the memory and actual usage depends on things like the number of concurrent users. E.g., on my laptop, the backend consumes a bit under 1 GB with at most a 1 concurrent user. dev3 currently uses around 2.2 GB. On the other hand, the frontend on dev3 currently is using <10 MB.
1 Like
Thanks both! This is very reassuring, I think - what do you think @michaelbontyes?
Wow 2.2GB is so different from 10MB - @ibacher why does your machine’s frontend require so much more memory on your dev3 instance?
The 2.2 GB number is for the backend on dev3… I was using it as an example of a much more heavily-used instance
1 Like
Meaning… 100’s of users? Millions of patients?
Definitely many fewer patients (< 100). The real driver for memory consumption, though, will be number of simultaneous users, which we currently don’t have a great way to capture. In any case, at any kind of scale like that, we’re hopefully talking about having a dedicated DB server and a beefier instance. To put it simply, to run something like AMPATH’s instance, you’d need a similarly beefy server.
1 Like