Yes, especially since the SQL query wouldn’t be able to find it (assuming the deletion has already taken place).
I googled around on what a REST DELETE response should contain.[1,2,3]. Per RFC 7231, a DELETE should return 202 Accepted if deletion hasn’t happened yet (doesn’t apply in our case), 204 No Content if the item has been deleted, or 200 OK if the item has been deleted and the response contains status information. Personally, I like the pattern of returning info about what was deleted (just like a docker rm command returns the name/id of what was removed). So, my bias would be to return 200 OK with the resource that was deleted and, if implementing HATEOAS, putting relevant links in headers.
In any case, the changes you made for logging are fine. I just had one last question about a suspicious-looking line when creating/saving markers:
response = response.id;
I commented in the PR. If my assumption is right, we can create a separate ticket for addressing that “hack” and I’ll merge this PR.
About the suspicious line, the old API used to return only the id, so I sort of followed that whenever I wrote POST or PATCH notes. Is it ok if I create a new issue for returning whole resources during POST, PATCH, and DELETE routes? For POST and PATCH, do I use SELECT to return data or am I free to return the data passed to the server, along with the new id and dates?
Any REST endpoint that creates or saves resource(s) should respond with the corresponding resources. If the server has data that it writes to the database, I think it’s fine to respond with those data after the INSERT or UPDATE (or UPSERT) returns successfully – i.e., trust the database is working properly – without performing a SELECT to fetch what was just written. The exception would be if any data are being created by the database (e.g., if the database is creating/changing timestamps instead of just writing a value supplied by node, adding an auto-increment id, etc.); in these cases (where the database has generated or altered any data), the SELECT would be needed to ensure that what you return to the client is a precise representation of the resource in the database.
@heliostrike, atlas-stg.openmrs.org is looking great! The extra 6 months before fading looks like a better choice. All the operations & testing I’ve done so far are behaving as expected. I think this is ready for deployment!
I’ve added you as a collaborator on the openmrs-contrib-atlas repository. This means you have write access and can push to the repo or merge PRs. Remember what Spiderman taught us: “With great power comes great responsibility.” Correcting typos or obvious one-liner corrections can be committed directly without a PR. It’s still good to use PRs to get more than one pair of eyes on the code, so continue to code from tickets & submit PRs for the chunks of work. But we’ll have you merge some of your own PRs going forward and we’ll see if I can submit a PR for you to review & merge before summer ends.
Next, you’ll need to coordinate with @cintiadr as you work through the process of converting the 3.x branch into the new master branch and tagging it as 3.1 for deployment. I think the steps I mentioned earlier should allow you to turn 3.x into the new master branch without losing the history of master and, more importantly, being kind to anyone who might have already forked/cloned the repository (I just googled those steps… so feel free to double-check me and second-guess anything that looks wrong).
Since our infrastructure is deployed using ansible & docker containers, I would expect something like:
Check in with @cintiadr to review the steps you’re going to take and to make sure there aren’t any steps she needs to take before you proceed.
You clone the openmrs/openmrs-contrib-atlas repo directly (not through your fork), convert 3.x to master (ideally using steps like I found above so git history is maintained), create a 3.1 tag and push these changes to github
At this point, the openmrs repo should have your 3.1 code on the master branch, the 3.x branch is gone, and there’s a 3.1 tag from head of master.
@cintiadr updates the atlas docker image from the new 3.1 tag and then deploys this to production
You validate with @cintiadr that ldap is working as expected and then we all do a little dance!
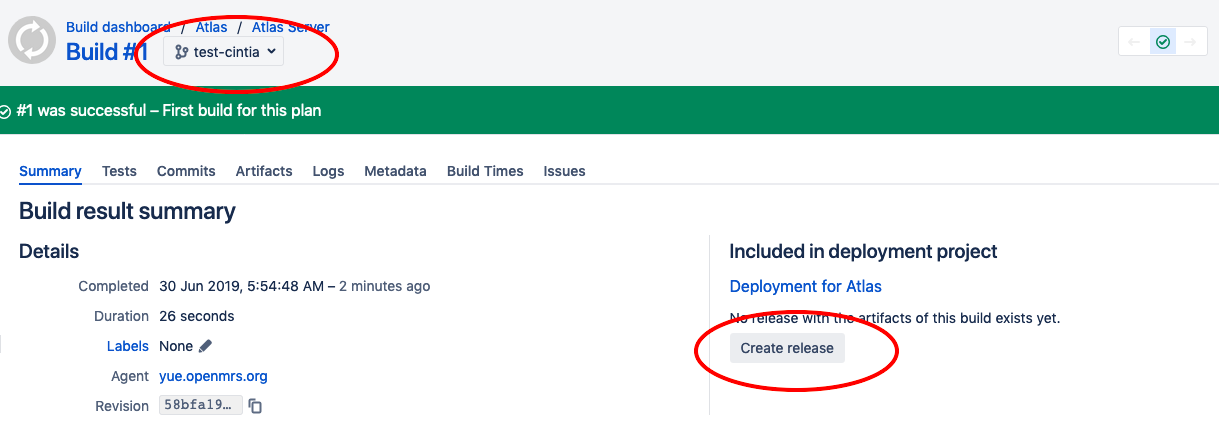
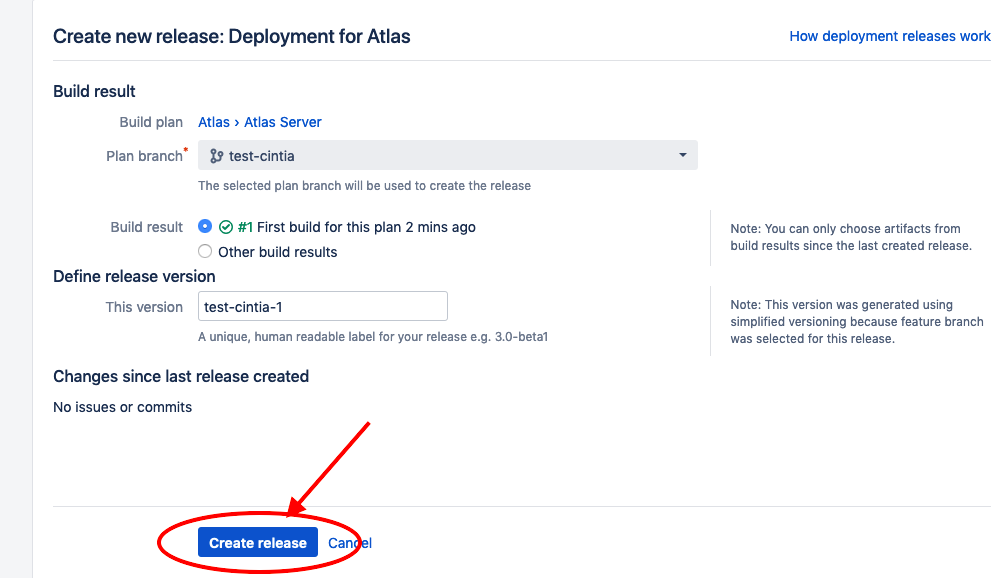
A CI build pointing to master, which now has the node code. That can be used to deploy to staging (as I’ve done it) and push the production tag to dockerhub.
A [git tag 3.1-rc1] for the commit I just pushed to staging.
I will need to do a little bit of ldap magic to give access to those interested, as it won’t be on by default. I assume I can do that next weekend.
I started working on ATLAS-175 when I realized that a site’s data on the front-end contains 2 keys ‘created_by’ and ‘uid’ containing the creator’s username. The only problem this will cause is that the GET and POST/PATCH routes will have slightly different responses, with POST/PATCH containing an extra ‘uid’ key. I feel that ‘uid’ should be replaced with ‘created_by’ where ever used, to avoid weird hacks in the code. This also makes replacing site data as simple as sites[i].siteData = response . What do you think?
Fine by me. I’m not a fan of the term uid anyway, since it is too easy to confuse with uuid. I think this was introduced during the initial switch to node and I don’t know what it’s used for beyond creator. Authorization should be handled separately in the auth table, so I can’t imagine needing to track another user for markers.
FYI - I created a ticket for security vulnerabilities that we should prioritize:
I just made a PR for it. I couldn’t view the vulnerabilities on the repo but @cintiadr had sent me a picture of the packages earlier. Let me know if any change is needed.
@cintiadr, I noticed changes in the CI plans for Atlas. Can you teach us how to deploy to staging and production properly? While we lean on you for help navigating big changes (e.g., new releases that depend on configuration or db changes), I’d prefer if we didn’t have to bother you for every new feature release.
I was able to find the deployment to staging, but it wasn’t clear to me how/where we would select a different branch from master if we wanted to deploy a feature branch to staging for testing before merging it to master. Or is that improper use of staging (i.e., counter to proper CI)?
If we have promoted features to staging and want to deploy that to production, is there a place where we provide the version name in CI and it automatically generates the tag in github for us? Or do we need to manually create the tag in github and then point the production deployment to the new tag?
I found a bug in my code that causes updating markers to fail when the user is not an admin. I mostly tested atlas as admin, so I didn’t catch this before. I described it and provided a fix for it in the ATLAS-180 PR.
@heliostrike, I commented on the PR. The value of created_by should be determined by the API (on the server). The client shouldn’t be setting this value. The value of created_by is the username of the authenticated user when the marker is created.
Indeed, I changed it so it will be simpler for others to deploy the commit they want whenever they want.
Mostly
If a release depends on configuration or DB changes, chances are it’s better to coordinate with me (as it can require changes to ansible). But that’s usually the exception, and it hasn’t been a problem for any of the other docker applications we are maintaining so far.
Well. Technically that’s ‘improper’ use of a CI/CD pipeline, but life is far from perfect and sometimes that’s needed anyway. The CD way is just decide which release candidate (e.g. the artifact generated by a green build in master) should be deployed to a certain environment, without any branches whatsoever.
If you have a branch (not a fork!), Bamboo will create a branch build for you after a few minutes (that’s a CI configuration):
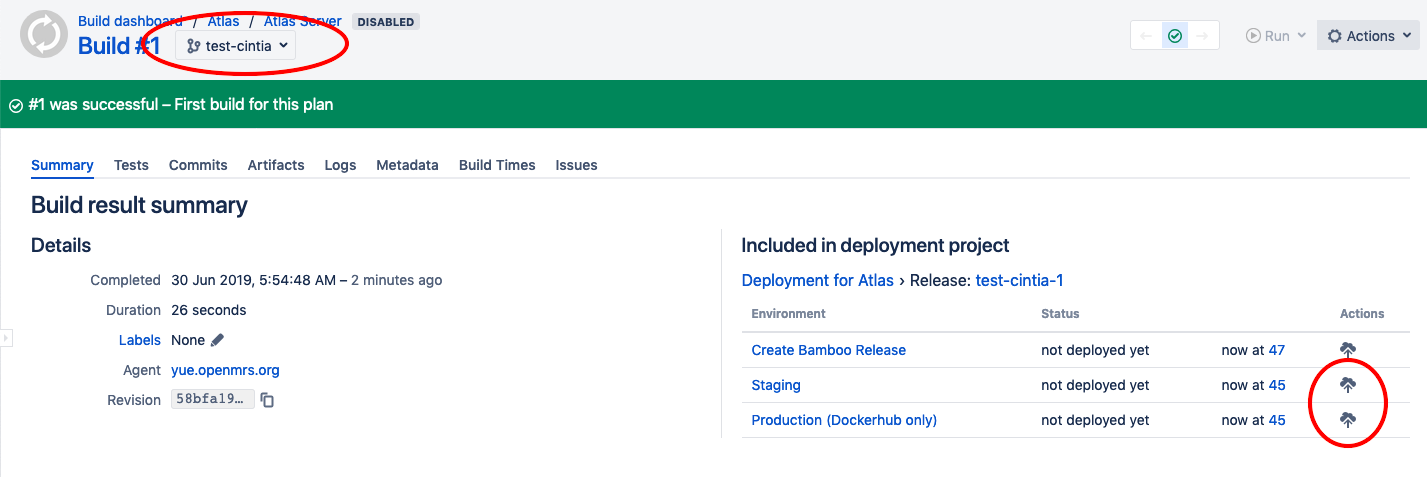
The deployment to staging will push a ‘staging’ tag to dockerhub (based on the image created on the build), and a deployment to production will push a ‘production’. So no manual work is required, it’s a matter of choosing the correct build number/commit and click the deploy button for this specific build.
For now, the atlas build only updates the ‘production’ docker tag in dockerhub, and it’s not yet used anywhere. After I update ansible, that deployment will not only deploy to dockerhub, but update the container running in the production machine.
Note that deployments belong to the same pipeline as the build, they are not independent.
So a deployment is configured to deploy the exact artefact generated by the build number it belongs to. It doesn’t matter if there are newer build numbers, newer commits to master, you have full control of which commit hash should be deployed to a certain environment. And in this case, ‘deploy’ means updating the docker tag AND updating the server to use the new docker image.
@burke@harsha89@cintiadr I submitted a PR for downloading marker data. I also attached the generated file, please have a look at it.
The generated csv contains distribution ids, instead of distribution names. I’ll work on rectifying it. Is there anything else?
I also created a PR for downloading map images too, with its own issues. Please have a look at it.
@burke@harsha89@cintiadr I think most of the bug tickets for the atlas server are solved, and most of the remaining tickets are features. Is there a ticket you’d like me to look at and prioritize?
I started reading the code of the atlas module. I think I sort of have a basic understanding of what it is doing, but I don’t understand why some of the calls being made are being made, or how they should be handled. Would it perhaps be possible to have a uberconference sometime to discuss how everything should be working? Till then, I’ll dig deeper into the code to understand how its doing what its doing. (If you send me a message and I don’t respond back in a day, there was probably a landslide in this cave I’m digging)
@burke@harsha89@cintiadr I’m not sure how the atlas module worked but 1 way I can imagine it working is:
The module’s ID is passed as a parameter through iframe, and is stored in the session. We’ll need to find a way to validate that this ID really belongs to a module.
Once logged in, users have a ‘Set main site’ option on their site (only when atlas is being accessed through a module). Clicking it maps the module’s ID to the site’s id.
From now on, when ever the module makes calls to update counts, we update the respective site.
You’ve got it. The module’s primary purpose is to render the OpenMRS Atlas in “module mode” (where the user can create the site for that server… the server running the module) and, in doing so, the linkages are made behind the scene so the module can send weekly, automated pings to the Atlas. I think we also had a prompt during marker creation that allowed the user to opt-out of sending stats or making them publicly viewable (setting the atlas.show_counts attribute).
Ideally, the module’s secret token would be generated by the module and passed to the server in the body of a request (i.e., using a POST instead of a GET which could expose the secret) when the marker is being created. The server would make the current user the creator and create an auth record with the module’s secret so – once ATLAS-166 is done – the module could send updates using its secret token.
 Correcting typos or obvious one-liner corrections can be committed directly without a PR. It’s still good to use PRs to get more than one pair of eyes on the code, so continue to code from tickets & submit PRs for the chunks of work. But we’ll have you merge some of your own PRs going forward and we’ll see if I can submit a PR for you to review & merge before summer ends.
Correcting typos or obvious one-liner corrections can be committed directly without a PR. It’s still good to use PRs to get more than one pair of eyes on the code, so continue to code from tickets & submit PRs for the chunks of work. But we’ll have you merge some of your own PRs going forward and we’ll see if I can submit a PR for you to review & merge before summer ends.