@mseaton option #2 seems the right one for me  .
.
Let’s make the problem simpler a bit for the start and display only one diagnosis (as one line) and the number of patients matching a given gender for that line (and not use the CompositionCohortDefinition yet):
Something like:
| Diagnosis | Males | Females |
|---------------|-------|---------|
| Encephalocele | 0 | 1 |
This is the intersection of the CodedObsCohortDefinition (set with the ‘Diagnosis’ question and with the ‘encephalocele’ concept as valueList) and two GenderCohortDefinition
Here is what I am doing now:
ReportDefinition rd = new ReportDefinition();
rd.setParameters(getParameters());
...
CohortCrossTabDataSetDefinition OPDConsult = new CohortCrossTabDataSetDefinition();
CodedObsCohortDefinition diag = new CodedObsCohortDefinition();
diag.addParameter(new Parameter("onOrAfter", "On Or After", Date.class));
diag.addParameter(new Parameter("onOrBefore", "On Or Before", Date.class));
diag.setOperator(SetComparator.IN);
diag.setQuestion(conceptService.getConceptByUuid("81c7149b-3f10-11e4-adec-0800271c1b75"));
diag.setValueList(Arrays.asList(conceptService.getConceptByUuid("f35731b9-4e14-11e4-8a57-0800271c1b75")));
Map<String, Object> parameterMappings = new HashMap<String, Object>();
parameterMappings.put("onOrAfter", "${startDate}");
parameterMappings.put("onOrBefore", "${endDate}");
// Add the 'Encephalocele' row
OPDConsult.addRow(concept.getDisplayString(), diag, parameterMappings);
// Add the 'Males' column
GenderCohortDefinition males = new GenderCohortDefinition();
males.setMaleIncluded(true);
OPDConsult.addColumn("Males", males, null);
// Add the 'Females' column
GenderCohortDefinition females = new GenderCohortDefinition();
females.setFemaleIncluded(true);
OPDConsult.addColumn("Females", females, null);
rd.addDataSetDefinition("Outpatient Consultation", Mapped.mapStraightThrough(OPDConsult));
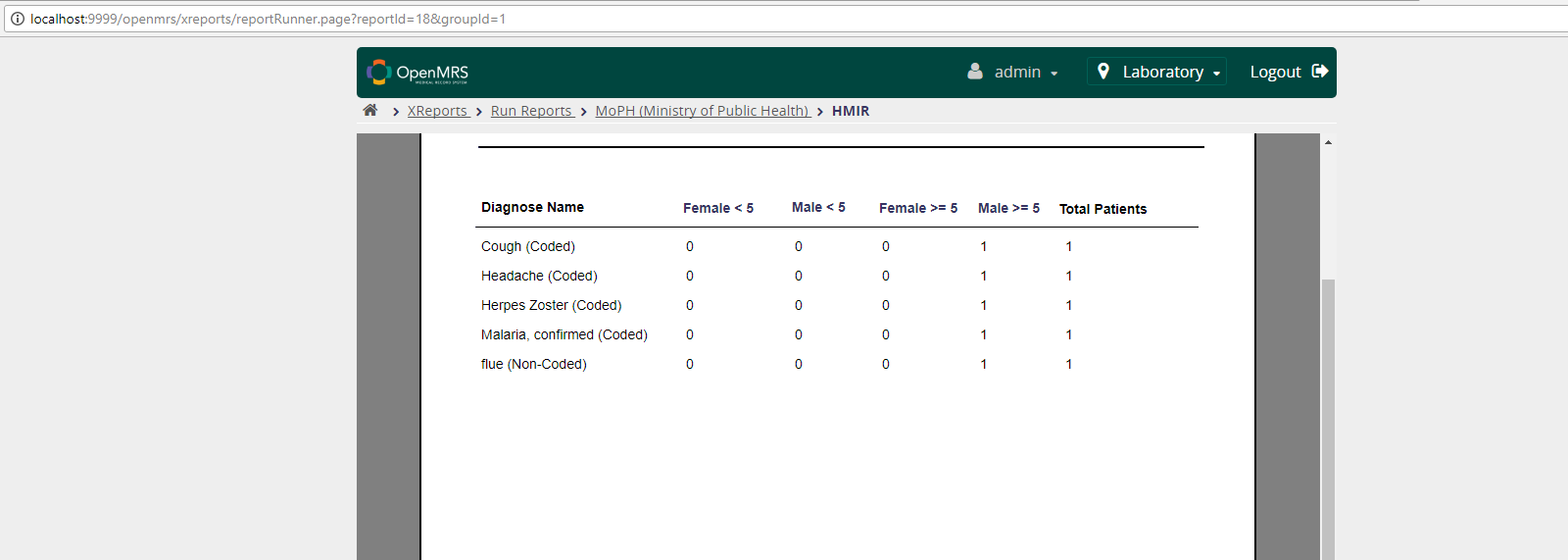
This returns the following table:
Even though one female patient has an ‘encephalocele’ diagnosis, the table shows empty.
While debugging I can see that the diag CodedObsCohortDef is correctly returning this matching person, ie [70].
However males and females GenderCohortDefs are returning an empty array.
(Q) Am I using them correctly?
(Q) In the example above the report parameters are not taken into account at all. Should I pass the mapping a bit differently? (I notice that the ‘addColumn’ method does not require a ‘String’ as parameters but rather directly parameter map)
Thanks
Romain






 , I will pull these changes and try again.
, I will pull these changes and try again.