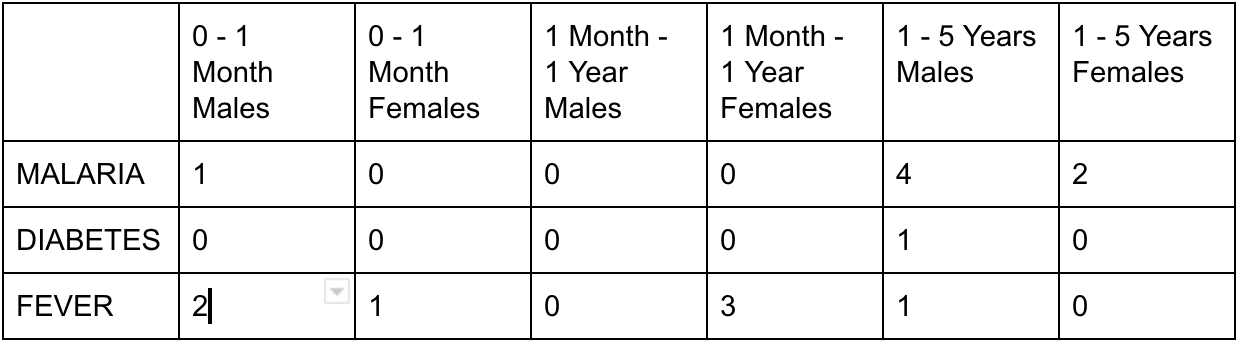
I have 3 diagnosis for which I want to get the total of all diagnosis recorded for patients in particular age groups. At first I was trying to add a row in a CohortCrossTabDataSetDefinition report where it had columns for each age/gender group and the rows where diagnosis and a cell contained the number of recorded diagnosis for each age group/gender. The table looked like below
The columns are a composition of gender and age cohort queries. And the rows CodedObsCohortDefinition for each diagnosis and the CohortCrossTabDataSetDefinition now get’s an intersection to produce the result as a Cohort.
Now I want to count the total number of diagnosis for a particular age/gender group. I tried adding a new row but the counts are not what I want. If person 1 is diagnosed for MALARIA and diabetes, the result is one which makes sense since just one patient has been added to the cohort. But I need to the result to be 2 reflecting that person 1 was diagnosed of 2 conditions.
The solution we decided to use was build separate report with just one row and then later combine the two reports to get the desired result.
Now I’m having a little trouble choosing a data set to use for the second report. I thought of using the sql data set where our report definition will be made up of multiple sql data sets for each age/gender category. But my concern with this approach is that I have to calculate age from birthdate inside the SQL query. This doesn’t sound like a very good idea.
Is it possible to use the AgeCohort together with the SQL Dataset? I mean like first filtering the patients using the age cohort and the sql data set is run on the result instead of running on the actual database table. Or which dataset is best for my use case?
@ivange94, your best bet in this case is likely to write a custom DataSetDefinition / DataSetDefinitionEvaluator that operates the way you want. You can use CohortDefinitions within your evaluator if that helps you keep your age/gender disaggregations consistently defined, but you will then need to write some custom code to get the number of unique diagnoses and filter them based on these Cohorts. Let me know if this is unclear if you need further guidance on this.
@mseaton thanks for your response. Is there a guide on how to implement one? I’ve been coping mostly by looking at implementations of existing classes. This is a little bit confusing as I have to look at a lot of class implementations to understand how the dataset is been used when the report is run. This also tends to bias my design based on a few existing implementations I’ve seen. What I would really like to know is how and when the dataset is used and how the result of the evaluation is returned. I noticed when I observed the ReportData returned by 2 different reports that used different datasets that the results are not the same. I mean in terms of presentation.
A direction I was hoping we could go would be for the column definitions to be a combination of:
GenderCohortDefinition
AgeCohortDefinition
CodedObsCohortDefinition
Where we would provide the whole value list of diagnoses to CodedObsCohortDefinition.
So that’s for the columns.
For the rows, we need only one that returns the evaluated cohorts combining 1, 2 and 3. Then what we aim at doing is extendEvaluatedCohort with a new member that is the obs count. It is important that we don’t intersect cohorts in the end with the mechanism of CohortCrossTabDataSetDefinition. What we have discovered is that the intersection kills off anything that is not strictly part of Cohort (here).
Of course this requires a custom evaluator bound to the row definition that will compile the obs count.
(Q.) If the above is a possibility, what could be the base for this row definition?
@ivange94, a custom data set is pretty easy to implement. You need 2 classes:
A class that extends BaseDataSetDefinition. To start with, this can be a totally empty class. You will add properties to it as needed as you go further (see below).
A class that implements DataSetEvaluator, and contains a class-level @Handler annotation that indicates it is able to evaluate your DataSetDefinition class you created above, eg:
The DataSetEvaluator is where all of the logic is placed. This is where you need to implement the actual code that queries your data and produces a DataSet. Most evaluators will construct and return an instance of SimpleDataSet, which is simply a construct that contains rows of data, each of which has columns of data. This data can be whatever you want.
Now, you will find in many/most cases that you want to enable some configuration of how your evaluator calculates data. Maybe you want to pass in a particular date range to limit things to, or you want to filter the rows returned or customize the columns returned in some way. Just like you would create a method that takes in parameters that can be operated to vary it’s results, you want your Evaluator to take in parameters to vary it’s results. The way this is done is by adding these parameters to your DataSetDefinition class. To do so, you simply add a bean-style property (private variable, public getter and setter) to your DataSetDefinition, and you annotate the private variable with a @ConfigurationProperty annotation. This signifies to the reporting framework that this particular property is meaningful to the resulting DataSet evaluation.
There are lots of examples of custom DataSetDefinition/DataSetEvaluator pairs out there. For a few places to look, you can look into the reporting module’s built-in classes, Definitions and related Evaluators, as well as those defined in modules like pihmalawi and mirebalaisreports .
@mksd, building on my reply above. Let’s say you have a custom data set definition+evaluator.
Now, if you never need to vary this in any way, you can just have an empty DSD and hard-code all of your logic into the evaluator like so:
Construct or fetch existing cohort definitions for each age category and gender of interest. (this can either be hard-coded into the evaluator if these will never change, or could be passed in as ConfigurationParameters on the Definition if you want to re-use this for other age/gender ranges at other times.
For each diagnosis concept, run a query to get a List of person ids for all distinct diagnoses (you can get other data too if useful, but I’m assuming you just need patient ids here). Importantly this should not return a Cohort or a Set, but rather a List - eg. every diagnosis should have a result. So this will be a List that might contain duplicates. Again, this can be hard-coded into the evaluator, or you could pass in the diagnoses of interest as a ConfigurationProperty on your definition.
Create your DataSet
Create a new SimpleDataSet
Iterate over these diagnosis lists, and for each:
Create a new DataSetRow
For each age+gender of interest, create a reduced List based on patients in the relevant Cohorts
Add a ColumnValue to your DataSetRow with the count from that reduced List
Return the DataSet
Obviously this is just one way to achieve all of this, and may not be the most efficient or elegant design. I’m just trying to illustrate how one might achieve this kind of behavior using the reporting module constructs. I’m sure you’ll come up logic far better than me.
@ivange94 - the ConfigurationProperty annotation basically indicates to the framework that a particular parameter with a particular name is supported by the definition. Ultimately, though, you need to add it as a Parameter to the definition instance in order for it to be passed in at runtime.
@mseaton I’m a little bit confused. When specifying the value of a configuration property as I’ve seen in some classes, the setter methods are called. But when adding parameters an addParameter* method is called. So I thought they are separate features.
@ivange94, if you want to set the value on the instance, you can simply call the setter on the configuration property itself. If you want to enable the value to be set at runtime via a parameter passed in via the EvaluationContext, then you need to add a Parameter to the instance, were the parameter name matches the configuration property name.